 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-agnostic Feature Importance and Effects with Dependent Features -- A Conditional Subgroup Approach
Paper and Code


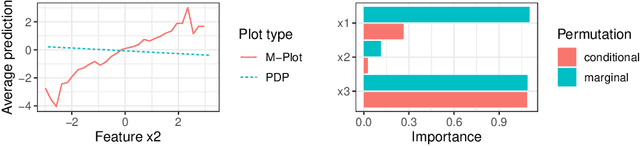
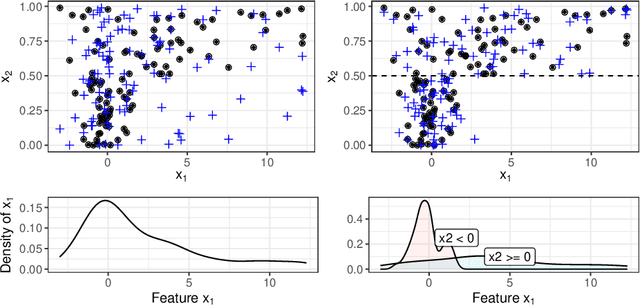
Partial dependence plots and permutation feature importance are popular model-agnostic interpretation methods. Both methods are based on predicting artificially created data points. When features are dependent, both methods extrapolate to feature areas with low data density. The extrapolation can cause misleading interpretations. To overcome extrapolation, we propose conditional variants of partial dependence plots and permutation feature importance. Our approach is based on perturbations in subgroups. The subgroups partition the feature space to make the feature distribution within a group more homogeneous and between the groups more heterogeneous. The interpretable subgroups enable additional local, nuanced interpretations of the feature dependence structure as well as the feature effects and importance values within the subgroups. We also introduce a data fidelity measure that captures the degree of extrapolation when data is transformed with a certain perturbation. In simulations and benchmarks on real data we show that our conditional interpretation methods reduce extrapolation. In an application we show that these methods provide more nuanced and richer explanations.