 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Aware Contrastive Instance Learning with Self-Distillation for Weakly-Supervised Audio-Visual Violence Detection
Paper and Code
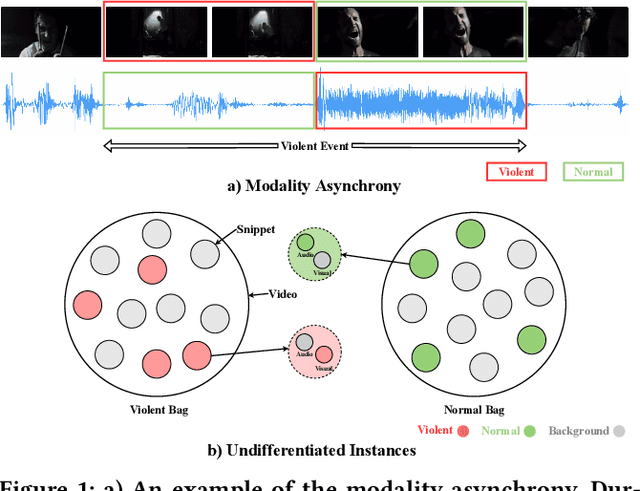
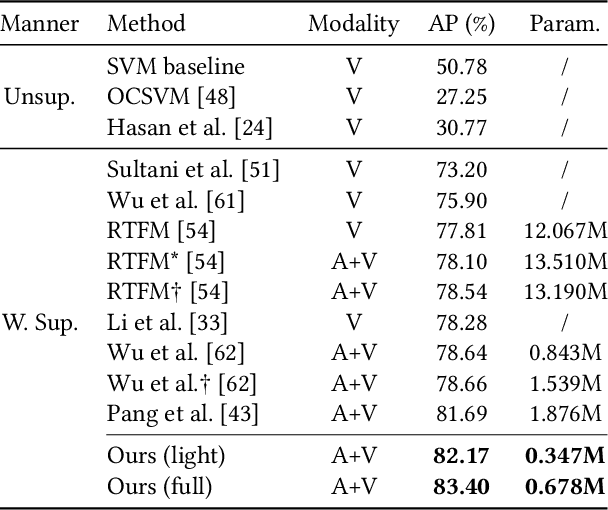
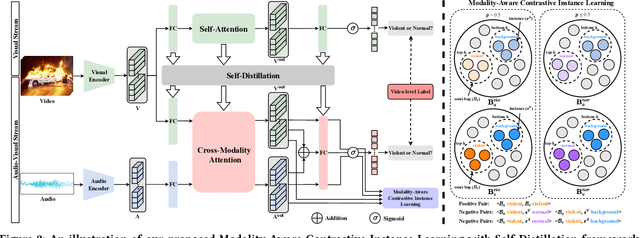
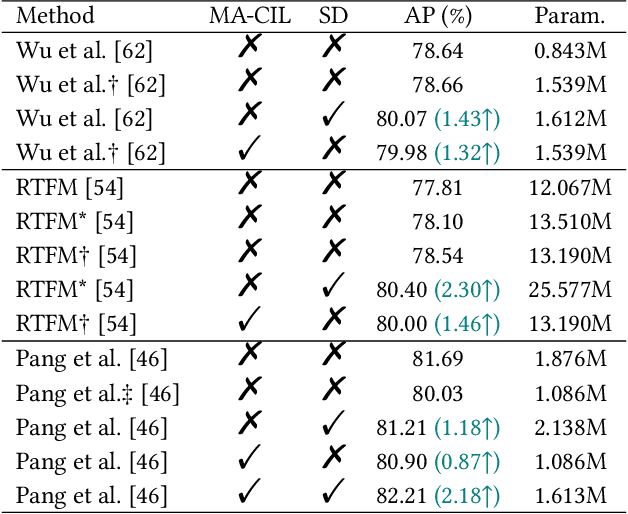
Weakly-supervised audio-visual violence detection aims to distinguish snippets containing multimodal violence events with video-level labels. Many prior works perform audio-visual integration and interaction in an early or intermediate manner, yet overlooking the modality heterogeneousness over the weakly-supervised setting. In this paper, we analyze the modality asynchrony and undifferentiated instances phenomena of the multiple instance learning (MIL) procedure, and further investigate its negative impact on weakly-supervised audio-visual learning. To address these issues, we propose a modality-aware contrastive instance learning with self-distillation (MACIL-SD) strategy. Specifically, we leverage a lightweight two-stream network to generate audio and visual bags, in which unimodal background, violent, and normal instances are clustered into semi-bags in an unsupervised way. Then audio and visual violent semi-bag representations are assembled as positive pairs, and violent semi-bags are combined with background and normal instances in the opposite modality as contrastive negative pairs. Furthermore, a self-distillation module is applied to transfer unimodal visual knowledge to the audio-visual model, which alleviates noises and closes the semantic gap between unimodal and multimodal features. Experiments show that our framework outperforms previous methods with lower complexity on the large-scale XD-Violence dataset. Results also demonstrate that our proposed approach can be used as plug-in modules to enhance other networks. Codes are available at https://github.com/JustinYuu/MACIL_SD.