 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-Powered Index Tuning: An Overview of Recent Progress and Open Challenges
Paper and Code
Aug 25, 2023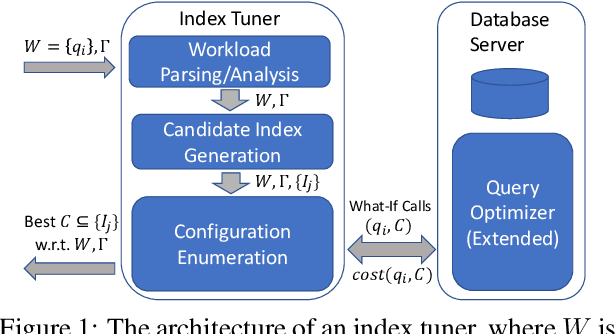

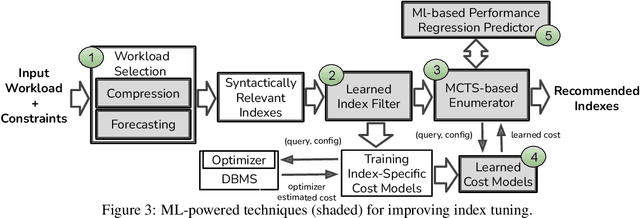
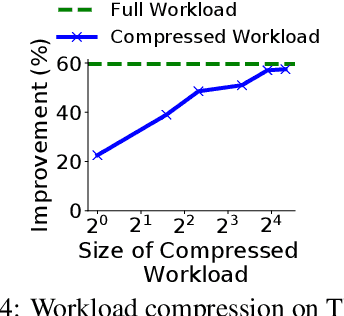
The scale and complexity of workloads in modern cloud services have brought into sharper focus a critical challenge in automated index tuning -- the need to recommend high-quality indexes while maintaining index tuning scalability. This challenge is further compounded by the requirement for automated index implementations to introduce minimal query performance regressions in production deployments, representing a significant barrier to achieving scalability and full automation. This paper directs attention to these challenges within automated index tuning and explores ways in which machine learning (ML) techniques provide new opportunities in their mitigation. In particular, we reflect on recent efforts in developing ML techniques for workload selection, candidate index filtering, speeding up index configuration search, reducing the amount of query optimizer calls, and lowering the chances of performance regressions. We highlight the key takeaways from these efforts and underline the gaps that need to be closed for their effective functioning within the traditional index tuning framework. Additionally, we present a preliminary cross-platform design aimed at democratizing index tuning across multiple SQL-like systems -- an imperative in today's continuously expanding data system landscape. We believe our findings will help provide context and impetus to the research and development efforts in automated index tuning.