 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Query Transformer: A Unified Image Segmentation Architecture
Paper and Code

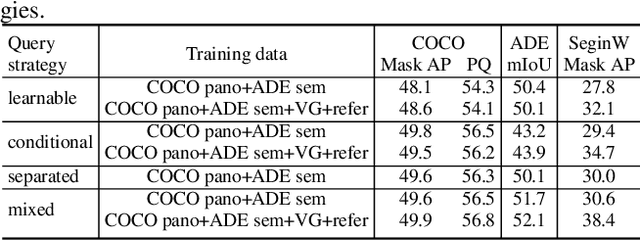


Existing unified image segmentation models either employ a unified architecture across multiple tasks but use separate weights tailored to each dataset, or apply a single set of weights to multiple datasets but are limited to a single task. In this paper, we introduce the Mixed-Query Transformer (MQ-Former), a unified architecture for multi-task and multi-dataset image segmentation using a single set of weights. To enable this, we propose a mixed query strategy, which can effectively and dynamically accommodate different types of objects without heuristic designs. In addition, the unified architecture allows us to use data augmentation with synthetic masks and captions to further improve model generalization. Experiments demonstrate that MQ-Former can not only effectively handle multiple segmentation datasets and tasks compared to specialized state-of-the-art models with competitive performance, but also generalize better to open-set segmentation tasks, evidenced by over 7 points higher performance than the prior art on the open-vocabulary SeginW benchmark.