 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemiRNA and Gene Expression based Cancer Classification using Self- Learning and Co-Training Approaches
Paper and Code
Jan 18, 2014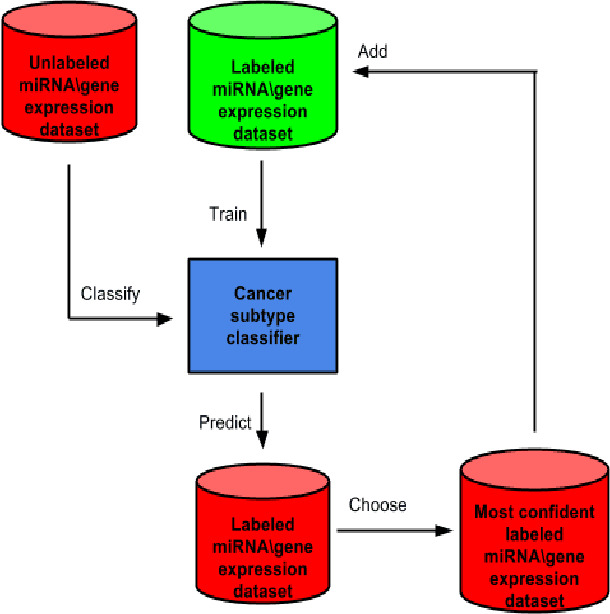
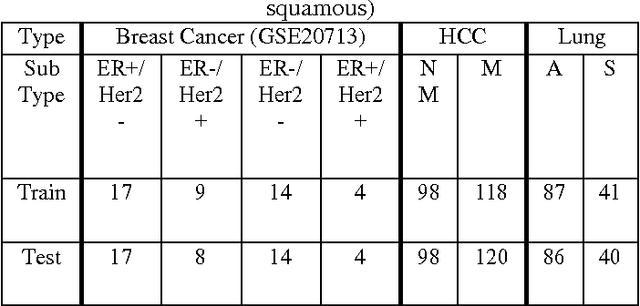

miRNA and gene expression profiles have been proved useful for classifying cancer samples. Efficient classifiers have been recently sought and developed. A number of attempts to classify cancer samples using miRNA/gene expression profiles are known in literature. However, the use of semi-supervised learning models have been used recently in bioinformatics, to exploit the huge corpuses of publicly available sets. Using both labeled and unlabeled sets to train sample classifiers, have not been previously considered when gene and miRNA expression sets are used. Moreover, there is a motivation to integrate both miRNA and gene expression for a semi-supervised cancer classification as that provides more information on the characteristics of cancer samples. In this paper, two semi-supervised machine learning approaches, namely self-learning and co-training, are adapted to enhance the quality of cancer sample classification. These approaches exploit the huge public corpuses to enrich the training data. In self-learning, miRNA and gene based classifiers are enhanced independently. While in co-training, both miRNA and gene expression profiles are used simultaneously to provide different views of cancer samples. To our knowledge, it is the first attempt to apply these learning approaches to cancer classification. The approaches were evaluated using breast cancer, hepatocellular carcinoma (HCC) and lung cancer expression sets. Results show up to 20% improvement in F1-measure over Random Forests and SVM classifiers. Co-Training also outperforms Low Density Separation (LDS) approach by around 25% improvement in F1-measure in breast cancer.