 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing the Effect of Noise and Limited Dataset Size in Image Classification Using Depth Estimation as an Auxiliary Task with Deep Multitask Learning
Paper and Code
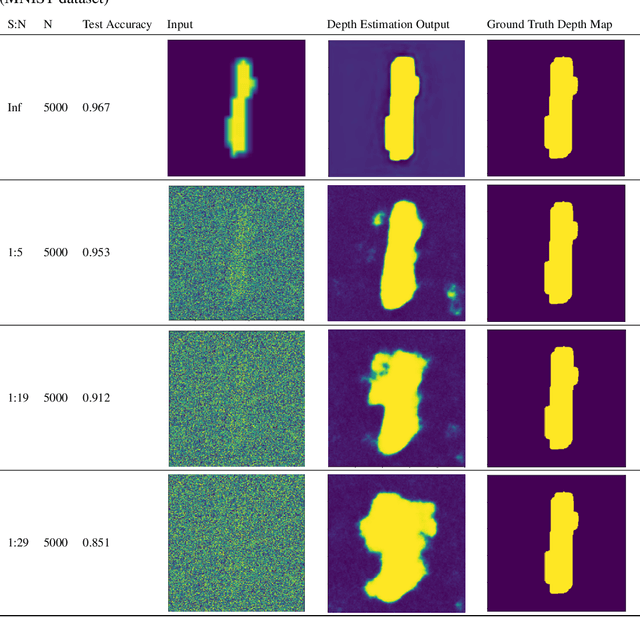


Generalizability is the ultimate goal of Machine Learning (ML) image classifiers, for which noise and limited dataset size are among the major concerns. We tackle these challenges through utilizing the framework of deep Multitask Learning (dMTL) and incorporating image depth estimation as an auxiliary task. On a customized and depth-augmented derivation of the MNIST dataset, we show a) multitask loss functions are the most effective approach of implementing dMTL, b) limited dataset size primarily contributes to classification inaccuracy, and c) depth estimation is mostly impacted by noise. In order to further validate the results, we manually labeled the NYU Depth V2 dataset for scene classification tasks. As a contribution to the field, we have made the data in python native format publicly available as an open-source dataset and provided the scene labels. Our experiments on MNIST and NYU-Depth-V2 show dMTL improves generalizability of the classifiers when the dataset is noisy and the number of examples is limited.