 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Optimal Algorithms for Adversarial Bandit Problem with Multiple Plays
Paper and Code
Nov 25, 2019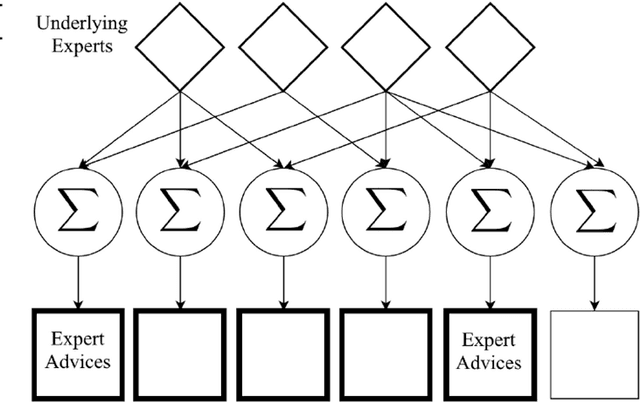
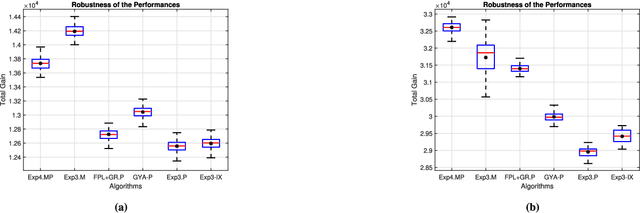
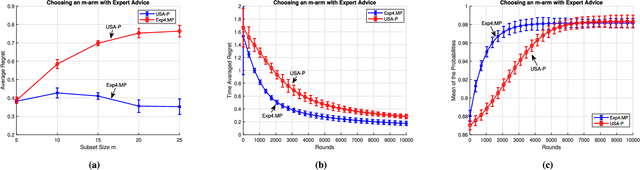
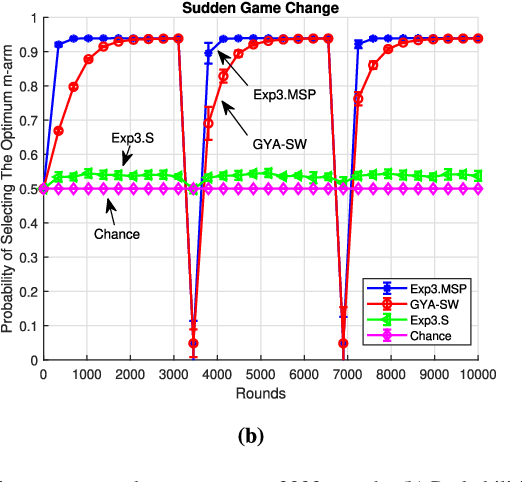
We investigate the adversarial bandit problem with multiple plays under semi-bandit feedback. We introduce a highly efficient algorithm that asymptotically achieves the performance of the best switching $m$-arm strategy with minimax optimal regret bounds. To construct our algorithm, we introduce a new expert advice algorithm for the multiple-play setting. By using our expert advice algorithm, we additionally improve the best-known high-probability bound for the multi-play setting by $O(\sqrt{m})$. Our results are guaranteed to hold in an individual sequence manner since we have no statistical assumption on the bandit arm gains. Through an extensive set of experiments involving synthetic and real data, we demonstrate significant performance gains achieved by the proposed algorithm with respect to the state-of-the-art algorithms.