 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Iterative Dynamic Game: Application to Nonlinear Robot Control Tasks
Paper and Code
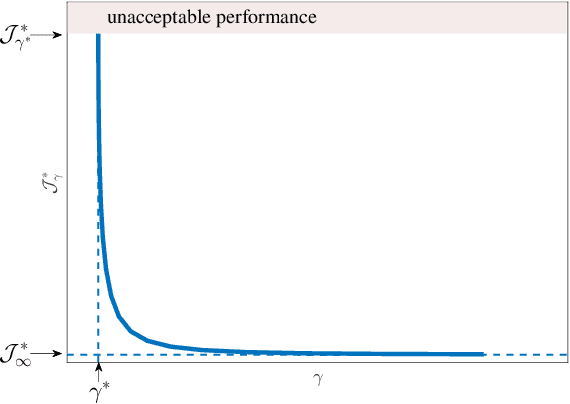
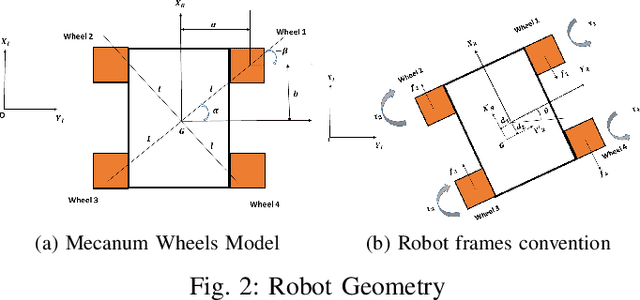
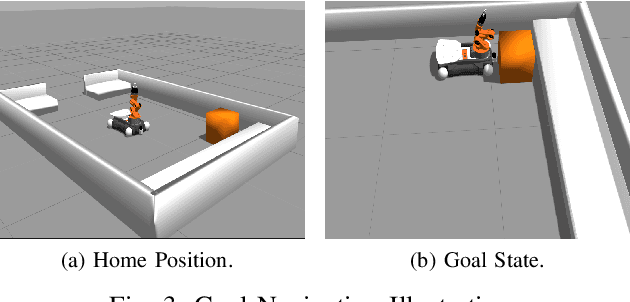

Multistage decision policies provide useful control strategies in high-dimensional state spaces, particularly in complex control tasks. However, they exhibit weak performance guarantees in the presence of disturbance, model mismatch, or model uncertainties. This brittleness limits their use in high-risk scenarios. We present how to quantify the sensitivity of such policies in order to inform of their robustness capacity. We also propose a minimax iterative dynamic game framework for designing robust policies in the presence of disturbance/uncertainties. We test the quantification hypothesis on a carefully designed deep neural network policy; we then pose a minimax iterative dynamic game (iDG) framework for improving policy robustness in the presence of adversarial disturbances. We evaluate our iDG framework on a mecanum-wheeled robot, whose goal is to find a ocally robust optimal multistage policy that achieve a given goal-reaching task. The algorithm is simple and adaptable for designing meta-learning/deep policies that are robust against disturbances, model mismatch, or model uncertainties, up to a disturbance bound. Videos of the results are on the author's website, http://ecs.utdallas.edu/~opo140030/iros18/iros2018.html, while the codes for reproducing our experiments are on github, https://github.com/lakehanne/youbot/tree/rilqg. A self-contained environment for reproducing our results is on docker, https://hub.docker.com/r/lakehanne/youbotbuntu14/