 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIM: Mutual Information Machine
Paper and Code
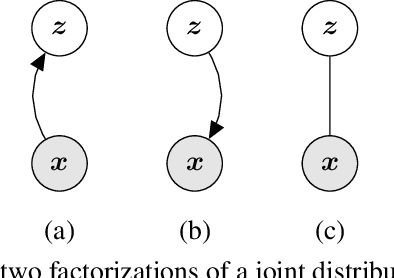
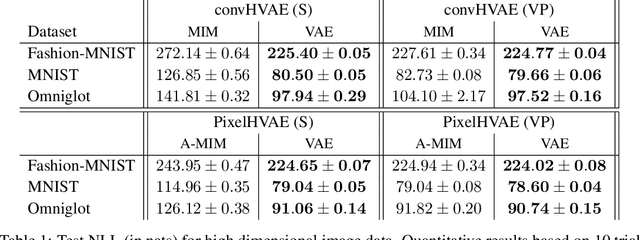
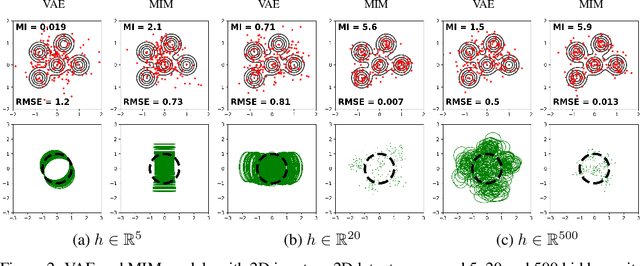

We introduce the Mutual Information Machine (MIM), an autoencoder model for learning joint distributions over observations and latent states. The model formulation reflects two key design principles: 1) symmetry, to encourage the encoder and decoder to learn consistent factorizations of the same underlying distribution; and 2) mutual information, to encourage the learning of useful representations for downstream tasks. The objective comprises the Jensen-Shannon divergence between the encoding and decoding joint distributions, plus a mutual information term. We show that this objective can be bounded by a tractable cross-entropy loss between the true model and a parameterized approximation, and relate this to maximum likelihood estimation and variational autoencoders. Experiments show that MIM is capable of learning a latent representation with high mutual information, and good unsupervised clustering, while providing data log likelihood comparable to VAE (with a sufficiently expressive architecture).