 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLoRA: Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning
Paper and Code
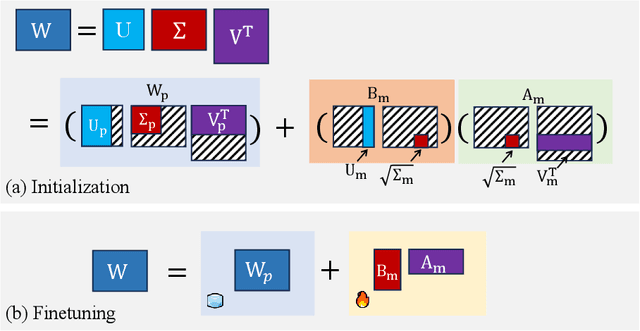
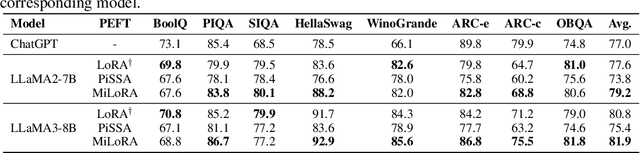
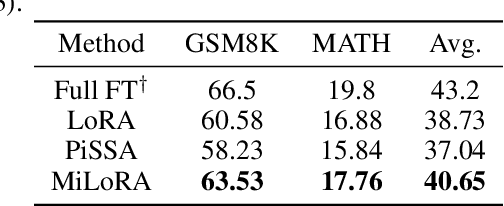
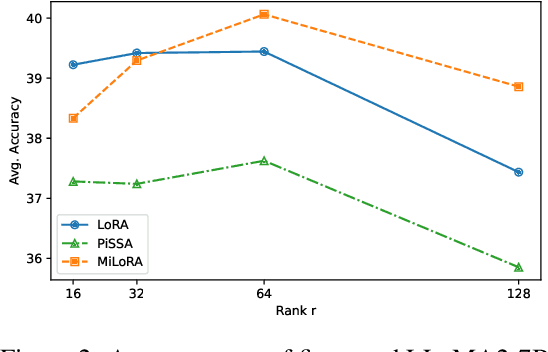
Efficient finetuning of large language models (LLMs) aims to adapt the LLMs with reduced computation and memory cost. Previous LoRA-based approaches initialize the low-rank matrices with gaussian distribution and zero values, while keeping the original weight matrices frozen. However, the trainable model parameters optimized in an unguided subspace might have interference with the well-learned subspace of the pretrained weight matrix. In this paper, we propose MiLoRA, a simple yet effective LLM finetuning approach that only updates the minor singular components of the weight matrix while keeping the principle singular components frozen. It is observed that the minor matrix corresponds to the noisy or long-tail information, while the principle matrix contains important knowledge. The MiLoRA initializes the low-rank matrices within a subspace that is orthogonal to the principle matrix, thus the pretrained knowledge is expected to be well preserved. During finetuning, MiLoRA makes the most use of the less-optimized subspace for learning the finetuning dataset. Extensive experiments on commonsense reasoning, math reasoning and instruction following benchmarks present the superior performance of our method.