 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-CT Synthesis and Inner Ear Super Resolution via Bayesian Generative Adversarial Networks
Paper and Code
Oct 27, 2020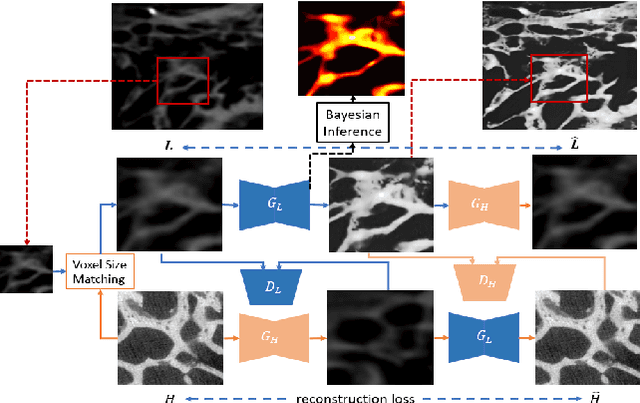
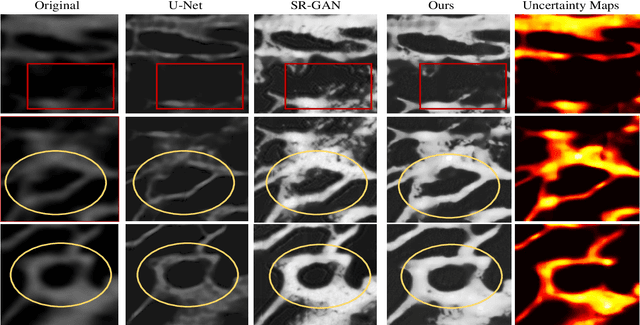
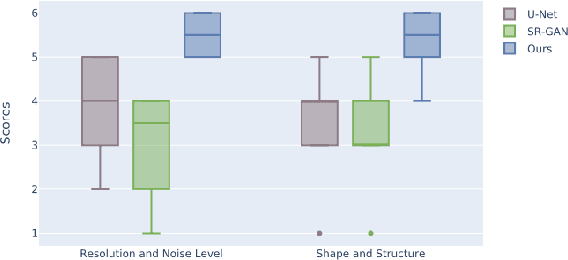

Existing medical image super-resolution methods rely on pairs of low- and high- resolution images to learn a mapping in a fully supervised manner. However, such image pairs are often not available in clinical practice. In this paper, we address super resolution problem in a real-world scenario using unpaired data and synthesize linearly \textbf{eight times} higher resolved Micro-CT images of temporal bone structure, which is embedded in the inner ear. We explore cycle-consistency generative adversarial networks for super-resolution task and equip the translation approach with Bayesian inference. We further introduce \emph{Hu Moment} the evaluation metric to quantify the structure of the temporal bone. We evaluate our method on a public inner ear CT dataset and have seen both visual and quantitative improvement over state-of-the-art deep-learning based methods. In addition, we perform a multi-rater visual evaluation experiment and find that trained experts consistently rate the proposed method highest quality scores among all methods. Implementing our approach as an end-to-end learning task, we are able to quantify uncertainty in the unpaired translation tasks and find that the uncertainty mask can provide structural information of the temporal bone.