 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIA-Former: Efficient and Robust Vision Transformers via Multi-grained Input-Adaptation
Paper and Code
Dec 21, 2021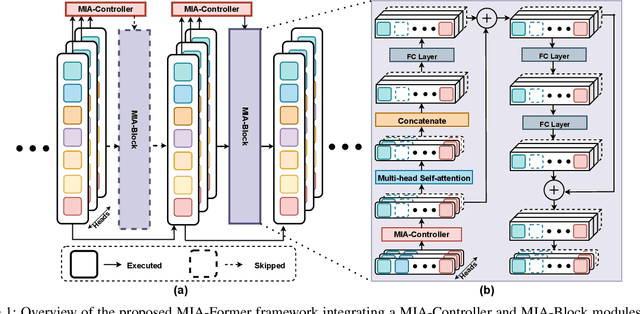
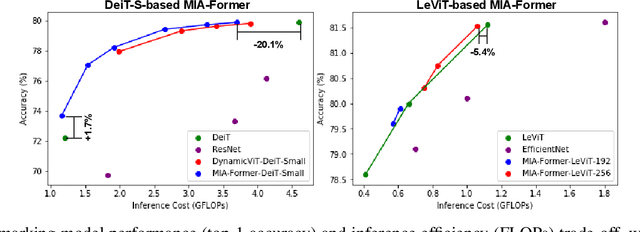
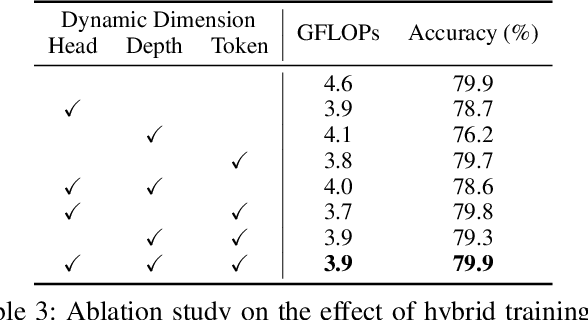
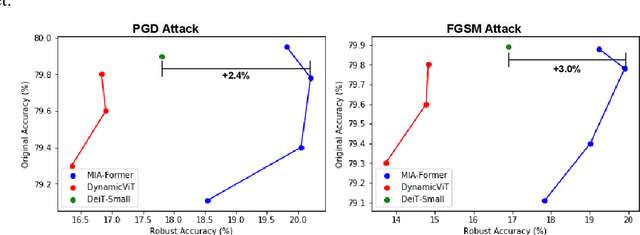
ViTs are often too computationally expensive to be fitted onto real-world resource-constrained devices, due to (1) their quadratically increased complexity with the number of input tokens and (2) their overparameterized self-attention heads and model depth. In parallel, different images are of varied complexity and their different regions can contain various levels of visual information, indicating that treating all regions/tokens equally in terms of model complexity is unnecessary while such opportunities for trimming down ViTs' complexity have not been fully explored. To this end, we propose a Multi-grained Input-adaptive Vision Transformer framework dubbed MIA-Former that can input-adaptively adjust the structure of ViTs at three coarse-to-fine-grained granularities (i.e., model depth and the number of model heads/tokens). In particular, our MIA-Former adopts a low-cost network trained with a hybrid supervised and reinforcement training method to skip unnecessary layers, heads, and tokens in an input adaptive manner, reducing the overall computational cost. Furthermore, an interesting side effect of our MIA-Former is that its resulting ViTs are naturally equipped with improved robustness against adversarial attacks over their static counterparts, because MIA-Former's multi-grained dynamic control improves the model diversity similar to the effect of ensemble and thus increases the difficulty of adversarial attacks against all its sub-models. Extensive experiments and ablation studies validate that the proposed MIA-Former framework can effectively allocate computation budgets adaptive to the difficulty of input images meanwhile increase robustness, achieving state-of-the-art (SOTA) accuracy-efficiency trade-offs, e.g., 20% computation savings with the same or even a higher accuracy compared with SOTA dynamic transformer models.