Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Learning from Imbalanced Data
Paper and Code
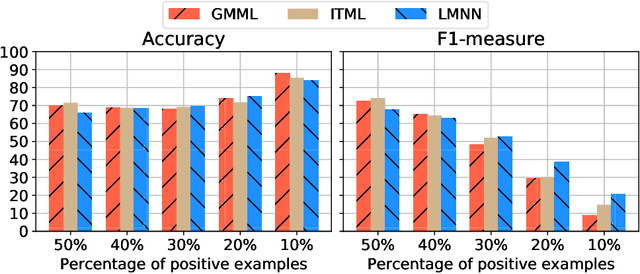
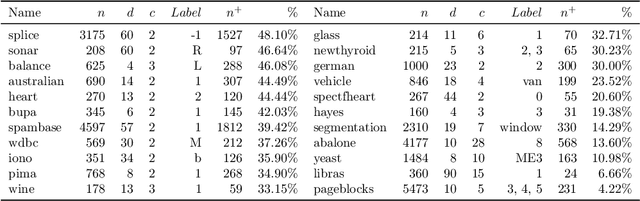
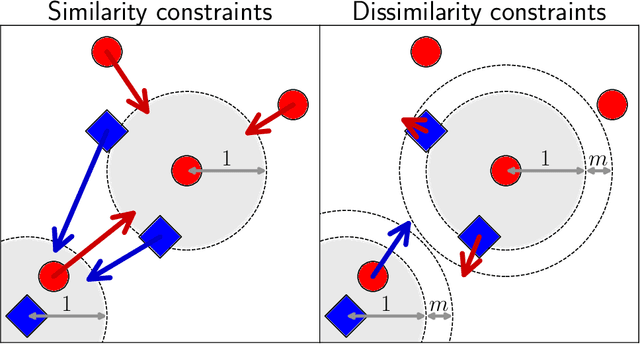
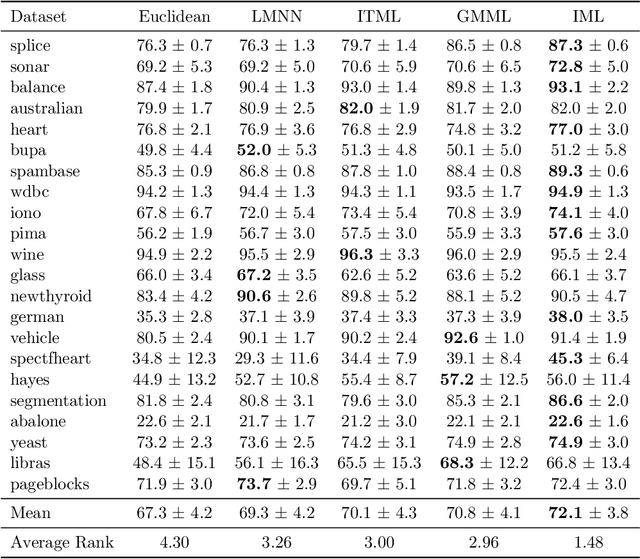
A key element of any machine learning algorithm is the use of a function that measures the dis/similarity between data points. Given a task, such a function can be optimized with a metric learning algorithm. Although this research field has received a lot of attention during the past decade, very few approaches have focused on learning a metric in an imbalanced scenario where the number of positive examples is much smaller than the negatives. Here, we address this challenging task by designing a new Mahalanobis metric learning algorithm (IML) which deals with class imbalance. The empirical study performed shows the efficiency of IML.
View paper on