 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric-Guided Prototype Learning
Paper and Code


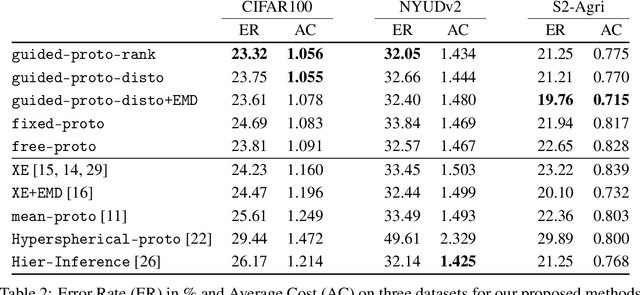

Not all errors are created equal. This is especially true for many key machine learning applications. In the case of classification tasks, the hierarchy of errors can be summarized under the form of a cost matrix, which assesses the gravity of confusing each pair of classes. When certain conditions are met, this matrix defines a metric, which we use in a new and versatile classification layer to model the disparity of errors. Our method relies on conjointly learning a feature-extracting network and a set of class representations, or prototypes, which incorporate the error metric into their relative arrangement. Our approach allows for consistent improvement of the network's prediction with regard to the cost matrix. Furthermore, when the induced metric contains insight on the data structure, our approach improves the overall precision. Experiments on three different tasks and public datasets -- from agricultural time series classification to depth image semantic segmentation -- validate our approach.