 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Sparse Principal Component Analysis
Paper and Code
Aug 19, 2022

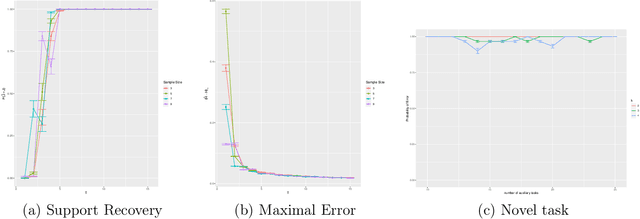

We study the meta-learning for support (i.e. the set of non-zero entries) recovery in high-dimensional Principal Component Analysis. We reduce the sufficient sample complexity in a novel task with the information that is learned from auxiliary tasks. We assume each task to be a different random Principal Component (PC) matrix with a possibly different support and that the support union of the PC matrices is small. We then pool the data from all the tasks to execute an improper estimation of a single PC matrix by maximising the $l_1$-regularised predictive covariance to establish that with high probability the true support union can be recovered provided a sufficient number of tasks $m$ and a sufficient number of samples $ O\left(\frac{\log(p)}{m}\right)$ for each task, for $p$-dimensional vectors. Then, for a novel task, we prove that the maximisation of the $l_1$-regularised predictive covariance with the additional constraint that the support is a subset of the estimated support union could reduce the sufficient sample complexity of successful support recovery to $O(\log |J|)$, where $J$ is the support union recovered from the auxiliary tasks. Typically, $|J|$ would be much less than $p$ for sparse matrices. Finally, we demonstrate the validity of our experiments through numerical simulations.