 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Knowledge Distillation
Paper and Code



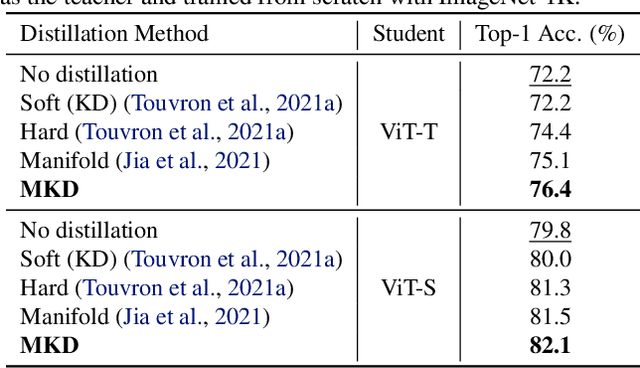
Recent studies pointed out that knowledge distillation (KD) suffers from two degradation problems, the teacher-student gap and the incompatibility with strong data augmentations, making it not applicable to training state-of-the-art models, which are trained with advanced augmentations. However, we observe that a key factor, i.e., the temperatures in the softmax functions for generating probabilities of both the teacher and student models, was mostly overlooked in previous methods. With properly tuned temperatures, such degradation problems of KD can be much mitigated. However, instead of relying on a naive grid search, which shows poor transferability, we propose Meta Knowledge Distillation (MKD) to meta-learn the distillation with learnable meta temperature parameters. The meta parameters are adaptively adjusted during training according to the gradients of the learning objective. We validate that MKD is robust to different dataset scales, different teacher/student architectures, and different types of data augmentation. With MKD, we achieve the best performance with popular ViT architectures among compared methods that use only ImageNet-1K as training data, ranging from tiny to large models. With ViT-L, we achieve 86.5% with 600 epochs of training, 0.6% better than MAE that trains for 1,650 epochs.