 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentor-KD: Making Small Language Models Better Multi-step Reasoners
Paper and Code

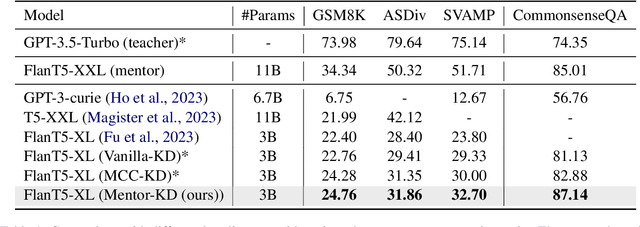
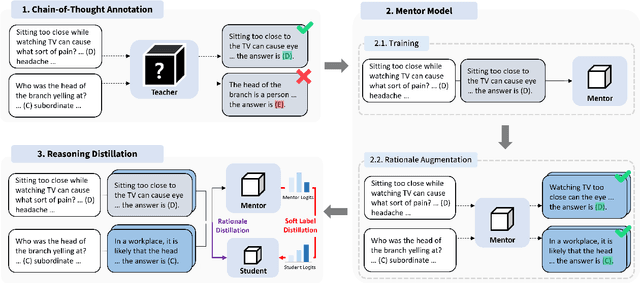
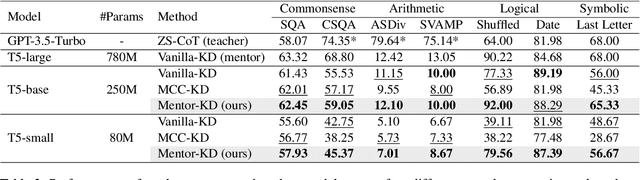
Large Language Models (LLMs) have displayed remarkable performances across various complex tasks by leveraging Chain-of-Thought (CoT) prompting. Recently, studies have proposed a Knowledge Distillation (KD) approach, reasoning distillation, which transfers such reasoning ability of LLMs through fine-tuning language models of multi-step rationales generated by LLM teachers. However, they have inadequately considered two challenges regarding insufficient distillation sets from the LLM teacher model, in terms of 1) data quality and 2) soft label provision. In this paper, we propose Mentor-KD, which effectively distills the multi-step reasoning capability of LLMs to smaller LMs while addressing the aforementioned challenges. Specifically, we exploit a mentor, intermediate-sized task-specific fine-tuned model, to augment additional CoT annotations and provide soft labels for the student model during reasoning distillation. We conduct extensive experiments and confirm Mentor-KD's effectiveness across various models and complex reasoning tasks.