 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory and Computation-Efficient Kernel SVM via Binary Embedding and Ternary Model Coefficients
Paper and Code
Oct 06, 2020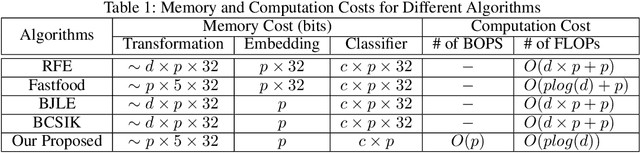
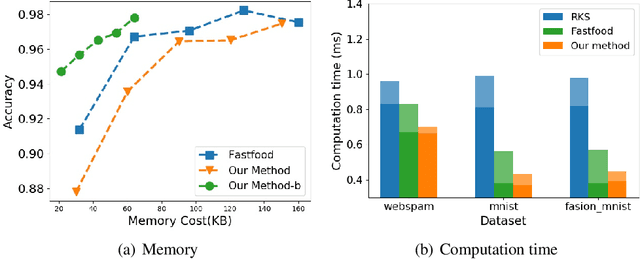
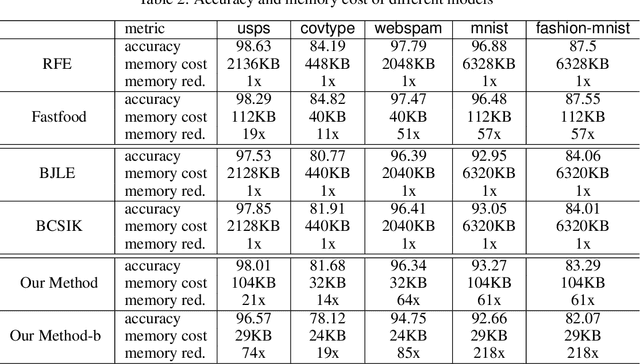
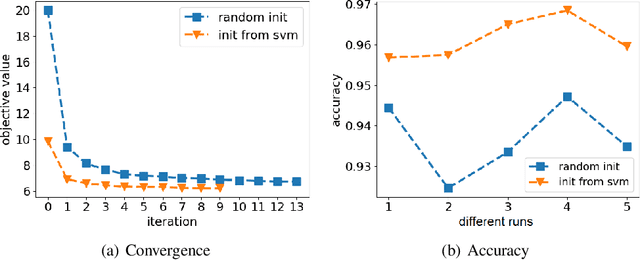
Kernel approximation is widely used to scale up kernel SVM training and prediction. However, the memory and computation costs of kernel approximation models are still too high if we want to deploy them on memory-limited devices such as mobile phones, smartwatches, and IoT devices. To address this challenge, we propose a novel memory and computation-efficient kernel SVM model by using both binary embedding and binary model coefficients. First, we propose an efficient way to generate compact binary embedding of the data, preserving the kernel similarity. Second, we propose a simple but effective algorithm to learn a linear classification model with ternary coefficients that can support different types of loss function and regularizer. Our algorithm can achieve better generalization accuracy than existing works on learning binary coefficients since we allow coefficient to be $-1$, $0$, or $1$ during the training stage, and coefficient $0$ can be removed during model inference for binary classification. Moreover, we provide a detailed analysis of the convergence of our algorithm and the inference complexity of our model. The analysis shows that the convergence to a local optimum is guaranteed, and the inference complexity of our model is much lower than other competing methods. Our experimental results on five large real-world datasets have demonstrated that our proposed method can build accurate nonlinear SVM models with memory costs less than 30KB.