 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoNet:Memorizing Representations of All Cross Features Efficiently via Multi-Hash Codebook Network for CTR Prediction
Paper and Code
Nov 03, 2022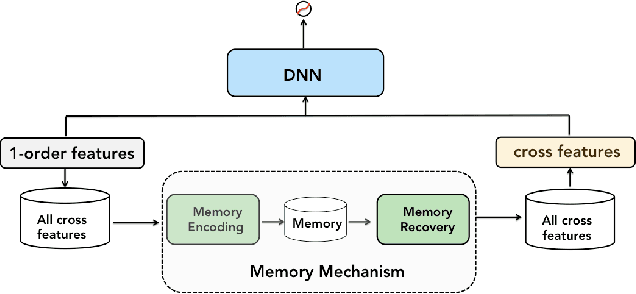
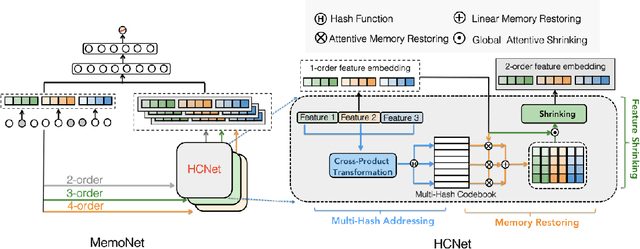
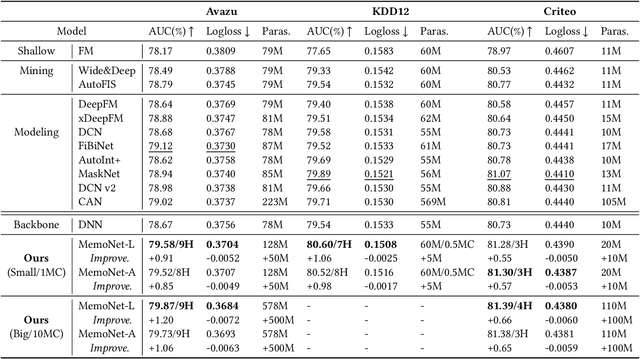
New findings in natural language processing(NLP) demonstrate that the strong memorization capability contributes a lot to the success of large language models.This inspires us to explicitly bring an independent memory mechanism into CTR ranking model to learn and memorize all cross features'representations. In this paper,we propose multi-Hash Codebook NETwork(HCNet) as the memory mechanism for efficiently learning and memorizing representations of all cross features in CTR tasks.HCNet uses multi-hash codebook as the main memory place and the whole memory procedure consists of three phases: multi-hash addressing,memory restoring and feature shrinking.HCNet can be regarded as a general module and can be incorporated into any current deep CTR model.We also propose a new CTR model named MemoNet which combines HCNet with a DNN backbone.Extensive experimental results on three public datasets show that MemoNet reaches superior performance over state-of-the-art approaches and validate the effectiveness of HCNet as a strong memory module.Besides, MemoNet shows the prominent feature of big models in NLP,which means we can enlarge the size of codebook in HCNet to sustainably obtain performance gains.Our work demonstrates the importance and feasibility of learning and memorizing representations of all cross features ,which sheds light on a new promising research direction.