 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks via Adversarial Examples
Paper and Code
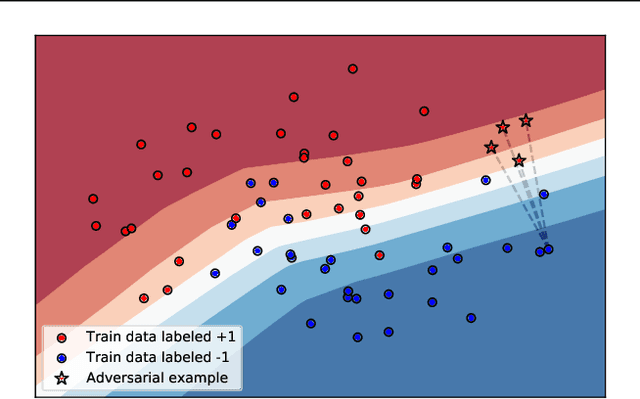



The raise of machine learning and deep learning led to significant improvement in several domains. This change is supported by both the dramatic rise in computation power and the collection of large datasets. Such massive datasets often include personal data which can represent a threat to privacy. Membership inference attacks are a novel direction of research which aims at recovering training data used by a learning algorithm. In this paper, we develop a mean to measure the leakage of training data leveraging a quantity appearing as a proxy of the total variation of a trained model near its training samples. We extend our work by providing a novel defense mechanism. Our contributions are supported by empirical evidence through convincing numerical experiments.