 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical SANSformers: Training self-supervised transformers without attention for Electronic Medical Records
Paper and Code
Aug 31, 2021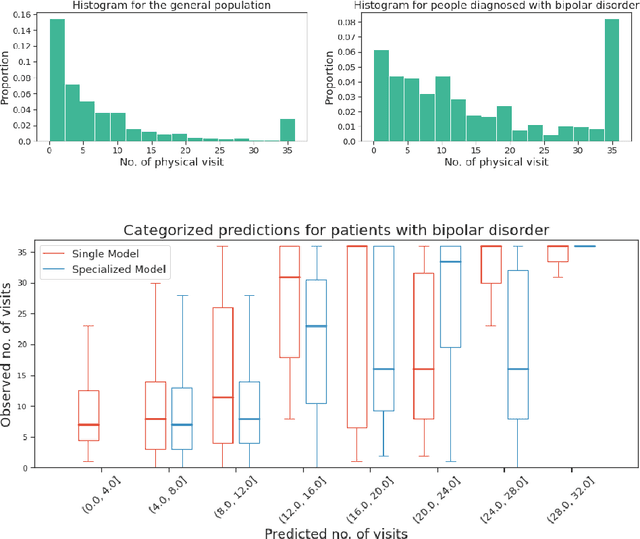


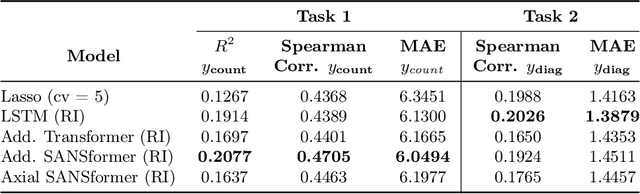
We leverage deep sequential models to tackle the problem of predicting healthcare utilization for patients, which could help governments to better allocate resources for future healthcare use. Specifically, we study the problem of \textit{divergent subgroups}, wherein the outcome distribution in a smaller subset of the population considerably deviates from that of the general population. The traditional approach for building specialized models for divergent subgroups could be problematic if the size of the subgroup is very small (for example, rare diseases). To address this challenge, we first develop a novel attention-free sequential model, SANSformers, instilled with inductive biases suited for modeling clinical codes in electronic medical records. We then design a task-specific self-supervision objective and demonstrate its effectiveness, particularly in scarce data settings, by pre-training each model on the entire health registry (with close to one million patients) before fine-tuning for downstream tasks on the divergent subgroups. We compare the novel SANSformer architecture with the LSTM and Transformer models using two data sources and a multi-task learning objective that aids healthcare utilization prediction. Empirically, the attention-free SANSformer models perform consistently well across experiments, outperforming the baselines in most cases by at least $\sim 10$\%. Furthermore, the self-supervised pre-training boosts performance significantly throughout, for example by over $\sim 50$\% (and as high as $800$\%) on $R^2$ score when predicting the number of hospital visits.