 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Concept Normalization in User Generated Texts by Learning Target Concept Embeddings
Paper and Code
Jun 07, 2020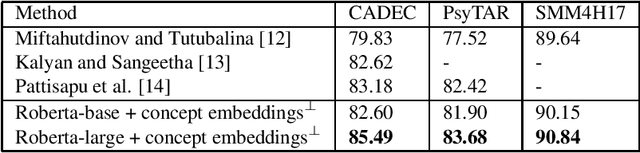
Medical concept normalization helps in discovering standard concepts in free-form text i.e., maps health-related mentions to standard concepts in a vocabulary. It is much beyond simple string matching and requires a deep semantic understanding of concept mentions. Recent research approach concept normalization as either text classification or text matching. The main drawback in existing a) text classification approaches is ignoring valuable target concepts information in learning input concept mention representation b) text matching approach is the need to separately generate target concept embeddings which is time and resource consuming. Our proposed model overcomes these drawbacks by jointly learning the representations of input concept mention and target concepts. First, it learns the input concept mention representation using RoBERTa. Second, it finds cosine similarity between embeddings of input concept mention and all the target concepts. Here, embeddings of target concepts are randomly initialized and then updated during training. Finally, the target concept with maximum cosine similarity is assigned to the input concept mention. Our model surpasses all the existing methods across three standard datasets by improving accuracy up to 2.31%.