 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediated Uncoupled Learning: Learning Functions without Direct Input-output Correspondences
Paper and Code
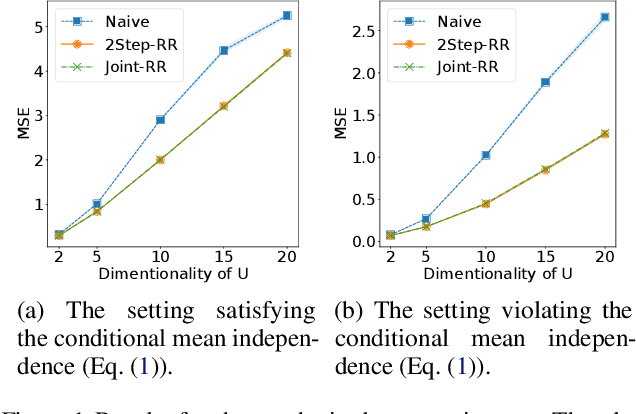



Ordinary supervised learning is useful when we have paired training data of input $X$ and output $Y$. However, such paired data can be difficult to collect in practice. In this paper, we consider the task of predicting $Y$ from $X$ when we have no paired data of them, but we have two separate, independent datasets of $X$ and $Y$ each observed with some mediating variable $U$, that is, we have two datasets $S_X = \{(X_i, U_i)\}$ and $S_Y = \{(U'_j, Y'_j)\}$. A naive approach is to predict $U$ from $X$ using $S_X$ and then $Y$ from $U$ using $S_Y$, but we show that this is not statistically consistent. Moreover, predicting $U$ can be more difficult than predicting $Y$ in practice, e.g., when $U$ has higher dimensionality. To circumvent the difficulty, we propose a new method that avoids predicting $U$ but directly learns $Y = f(X)$ by training $f(X)$ with $S_{X}$ to predict $h(U)$ which is trained with $S_{Y}$ to approximate $Y$. We prove statistical consistency and error bounds of our method and experimentally confirm its practical usefulness.