 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedian-Based Generation of Synthetic Speech Durations using a Non-Parametric Approach
Paper and Code
Nov 11, 2016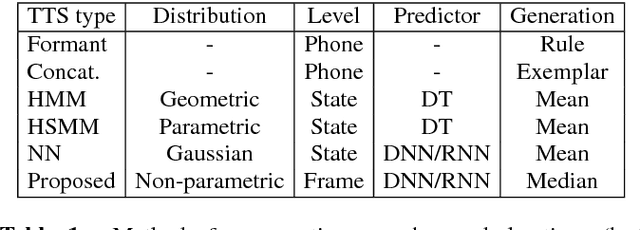
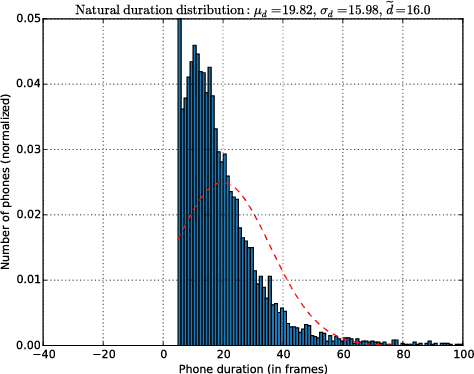
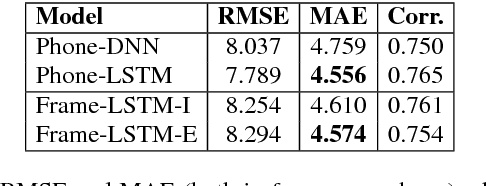
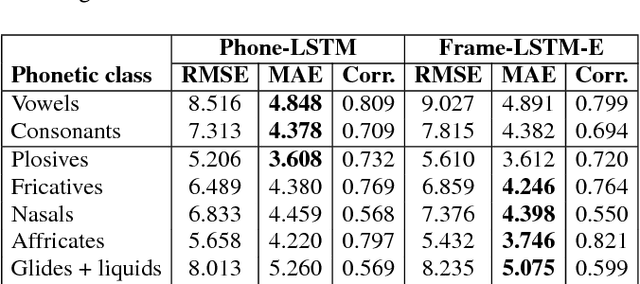
This paper proposes a new approach to duration modelling for statistical parametric speech synthesis in which a recurrent statistical model is trained to output a phone transition probability at each timestep (acoustic frame). Unlike conventional approaches to duration modelling -- which assume that duration distributions have a particular form (e.g., a Gaussian) and use the mean of that distribution for synthesis -- our approach can in principle model any distribution supported on the non-negative integers. Generation from this model can be performed in many ways; here we consider output generation based on the median predicted duration. The median is more typical (more probable) than the conventional mean duration, is robust to training-data irregularities, and enables incremental generation. Furthermore, a frame-level approach to duration prediction is consistent with a longer-term goal of modelling durations and acoustic features together. Results indicate that the proposed method is competitive with baseline approaches in approximating the median duration of held-out natural speech.