 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Disentanglement: A Review of Metrics
Paper and Code

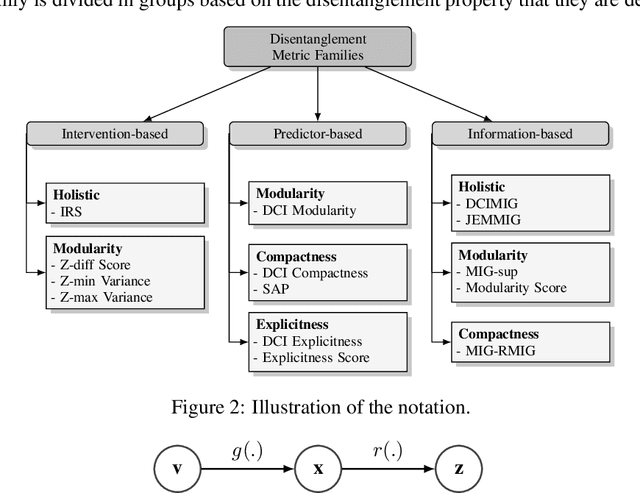
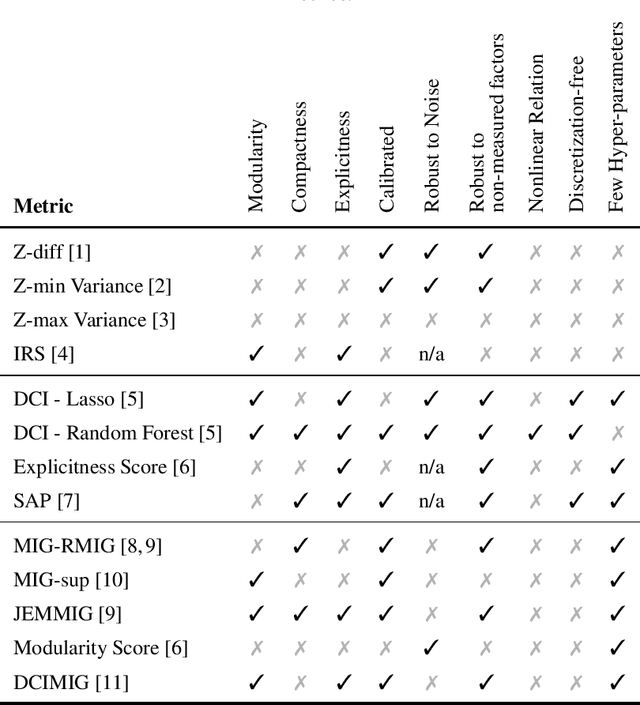
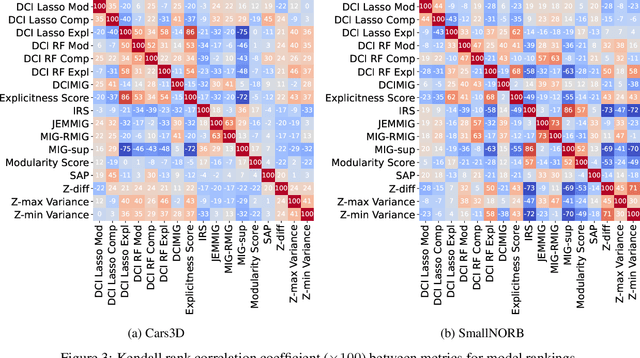
Learning to disentangle and represent factors of variation in data is an important problem in AI. While many advances are made to learn these representations, it is still unclear how to quantify disentanglement. Several metrics exist, however little is known on their implicit assumptions, what they truly measure and their limits. As a result, it is difficult to interpret results when comparing different representations. In this work, we survey supervised disentanglement metrics and thoroughly analyze them. We propose a new taxonomy in which all metrics fall into one of three families: intervention-based, predictor-based and information-based. We conduct extensive experiments, where we isolate representation properties to compare all metrics on many aspects. From experiment results and analysis, we provide insights on relations between disentangled representation properties. Finally, we provide guidelines on how to measure disentanglement and report the results.