 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Nyström Embeddings for Adaptive Compressive Learning
Paper and Code
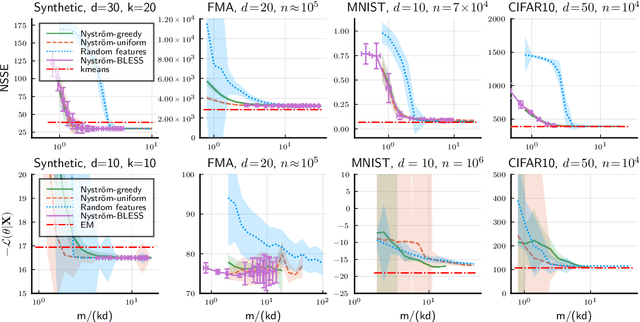
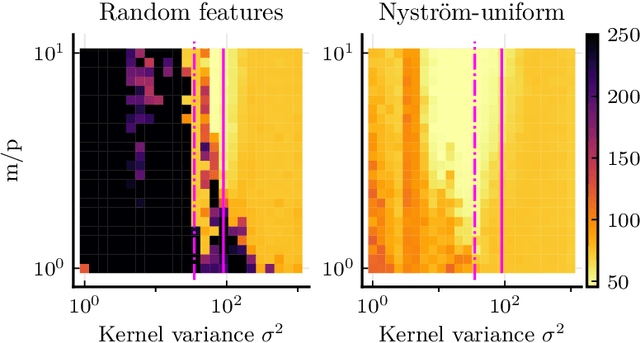
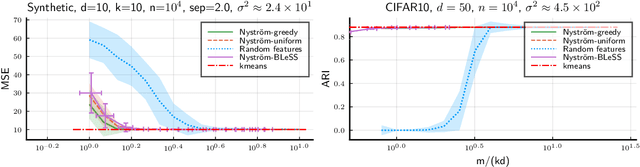
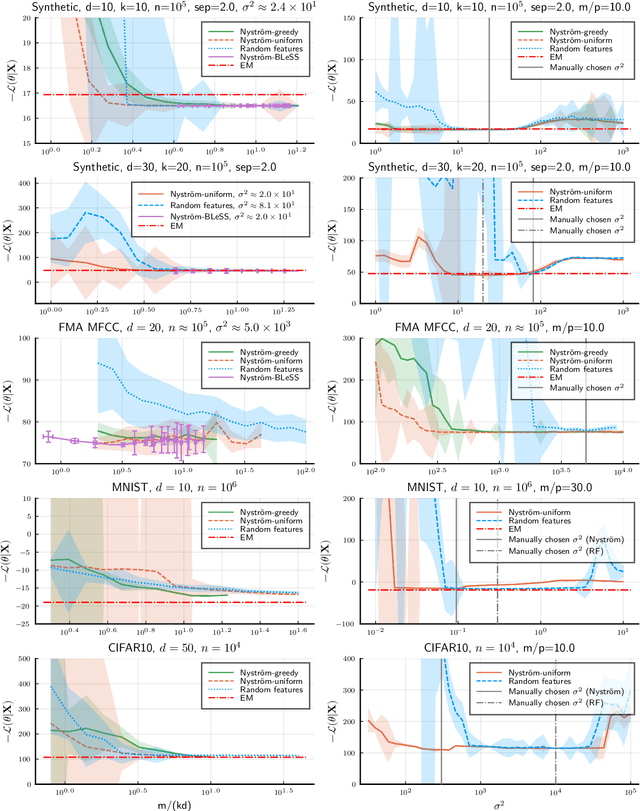
Compressive learning is an approach to efficient large scale learning based on sketching an entire dataset to a single mean embedding (the sketch), i.e. a vector of generalized moments. The learning task is then approximately solved as an inverse problem using an adapted parametric model. Previous works in this context have focused on sketches obtained by averaging random features, that while universal can be poorly adapted to the problem at hand. In this paper, we propose and study the idea of performing sketching based on data-dependent Nystr\"om approximation. From a theoretical perspective we prove that the excess risk can be controlled under a geometric assumption relating the parametric model used to learn from the sketch and the covariance operator associated to the task at hand. Empirically, we show for k-means clustering and Gaussian modeling that for a fixed sketch size, Nystr\"om sketches indeed outperform those built with random features.