 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation
Paper and Code
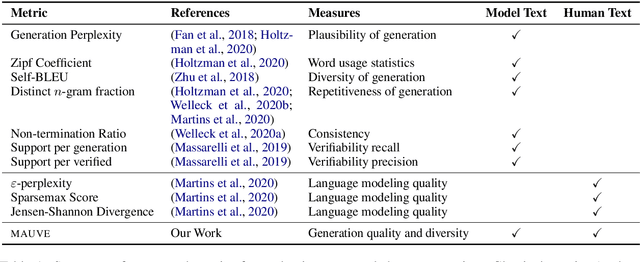
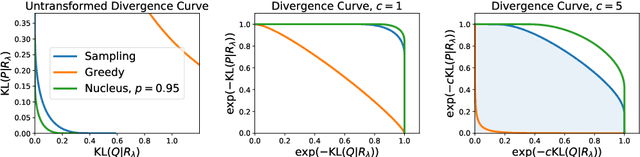
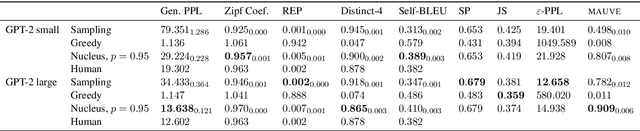
Despite major advances in open-ended text generation, there has been limited progress in designing evaluation metrics for this task. We propose MAUVE -- a metric for open-ended text generation, which directly compares the distribution of machine-generated text to that of human language. MAUVE measures the mean area under the divergence curve for the two distributions, exploring the trade-off between two types of errors: those arising from parts of the human distribution that the model distribution approximates well, and those it does not. We present experiments across two open-ended generation tasks in the web text domain and the story domain, and a variety of decoding algorithms and model sizes. Our results show that evaluation under MAUVE indeed reflects the more natural behavior with respect to model size, compared to prior metrics. MAUVE's ordering of the decoding algorithms also agrees with that of generation perplexity, the most widely used metric in open-ended text generation; however, MAUVE presents a more principled evaluation metric for the task as it considers both model and human text.