 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Low-Rank Trust Region Policy Optimization
Paper and Code
May 27, 2024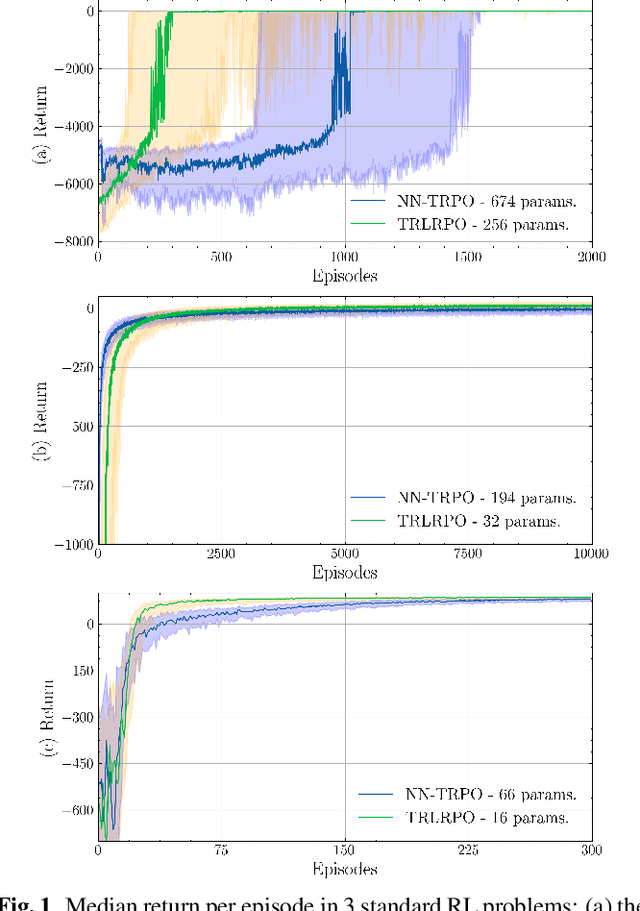
Most methods in reinforcement learning use a Policy Gradient (PG) approach to learn a parametric stochastic policy that maps states to actions. The standard approach is to implement such a mapping via a neural network (NN) whose parameters are optimized using stochastic gradient descent. However, PG methods are prone to large policy updates that can render learning inefficient. Trust region algorithms, like Trust Region Policy Optimization (TRPO), constrain the policy update step, ensuring monotonic improvements. This paper introduces low-rank matrix-based models as an efficient alternative for estimating the parameters of TRPO algorithms. By gathering the stochastic policy's parameters into a matrix and applying matrix-completion techniques, we promote and enforce low rank. Our numerical studies demonstrate that low-rank matrix-based policy models effectively reduce both computational and sample complexities compared to NN models, while maintaining comparable aggregated rewards.