 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Decision Processes with Continuous Side Information
Paper and Code
Nov 15, 2017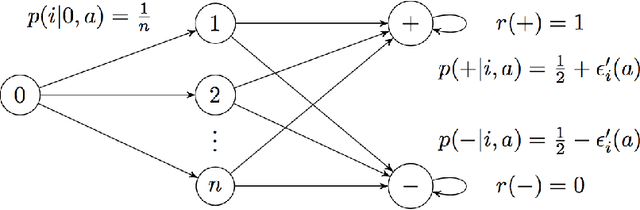
We consider a reinforcement learning (RL) setting in which the agent interacts with a sequence of episodic MDPs. At the start of each episode the agent has access to some side-information or context that determines the dynamics of the MDP for that episode. Our setting is motivated by applications in healthcare where baseline measurements of a patient at the start of a treatment episode form the context that may provide information about how the patient might respond to treatment decisions. We propose algorithms for learning in such Contextual Markov Decision Processes (CMDPs) under an assumption that the unobserved MDP parameters vary smoothly with the observed context. We also give lower and upper PAC bounds under the smoothness assumption. Because our lower bound has an exponential dependence on the dimension, we consider a tractable linear setting where the context is used to create linear combinations of a finite set of MDPs. For the linear setting, we give a PAC learning algorithm based on KWIK learning techniques.