 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarginal MAP Estimation for Inverse RL under Occlusion with Observer Noise
Paper and Code
Sep 16, 2021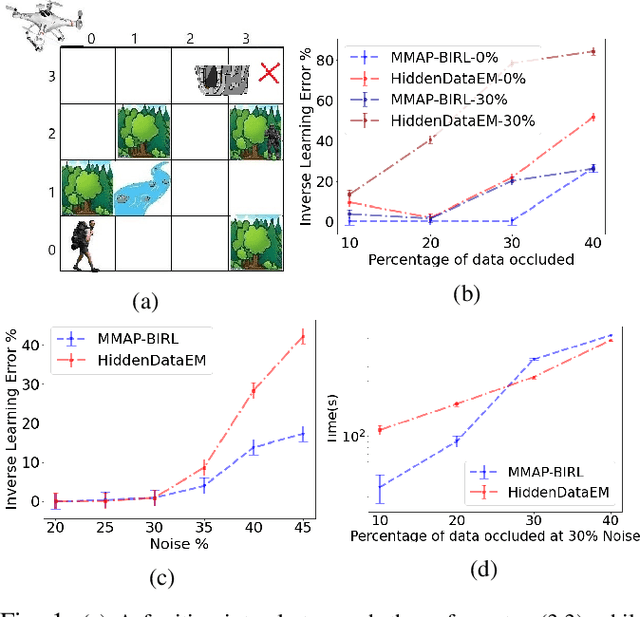



We consider the problem of learning the behavioral preferences of an expert engaged in a task from noisy and partially-observable demonstrations. This is motivated by real-world applications such as a line robot learning from observing a human worker, where some observations are occluded by environmental objects that cannot be removed. Furthermore, robotic perception tends to be imperfect and noisy. Previous techniques for inverse reinforcement learning (IRL) take the approach of either omitting the missing portions or inferring it as part of expectation-maximization, which tends to be slow and prone to local optima. We present a new method that generalizes the well-known Bayesian maximum-a-posteriori (MAP) IRL method by marginalizing the occluded portions of the trajectory. This is additionally extended with an observation model to account for perception noise. We show that the marginal MAP (MMAP) approach significantly improves on the previous IRL technique under occlusion in both formative evaluations on a toy problem and in a summative evaluation on an onion sorting line task by a robot.