 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-to-Many Voice Transformer Network
Paper and Code
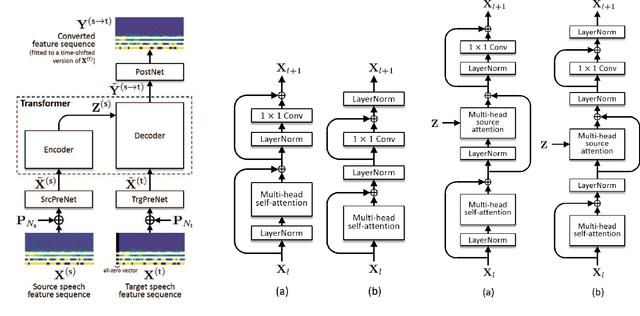
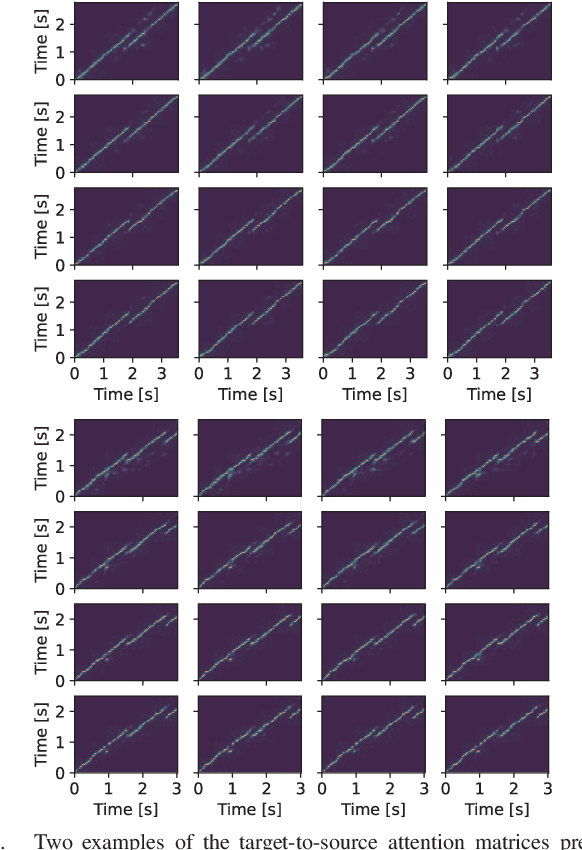
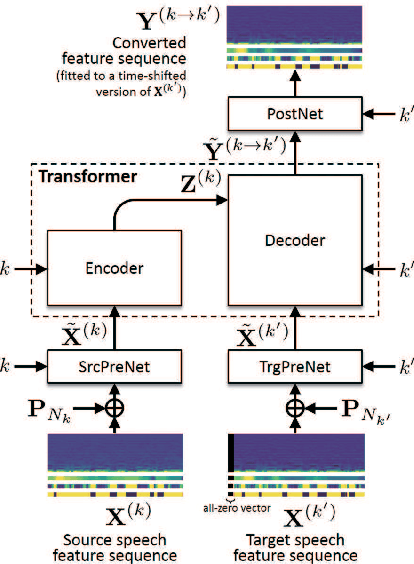
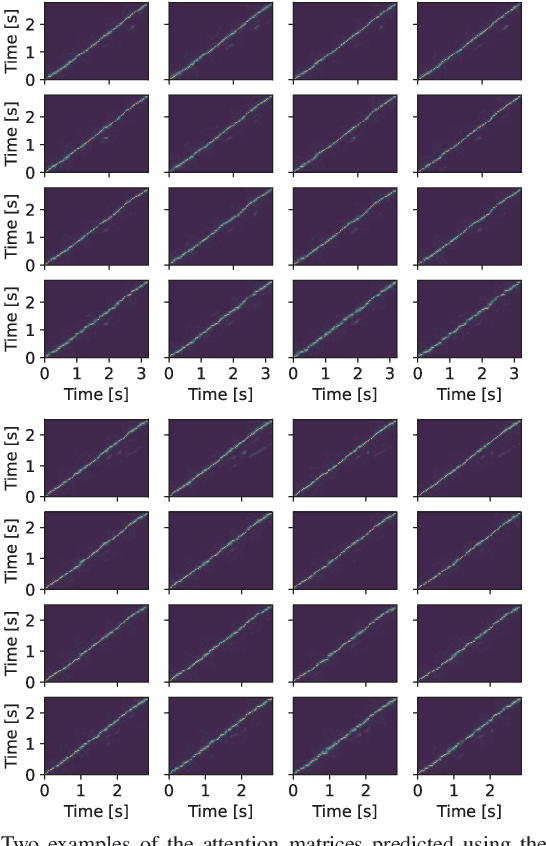
This paper proposes a voice conversion (VC) method based on a sequence-to-sequence (S2S) learning framework, which enables simultaneous conversion of the voice characteristics, pitch contour, and duration of input speech. We previously proposed an S2S-based VC method using a transformer network architecture called the voice transformer network (VTN). The original VTN was designed to learn only a mapping of speech feature sequences from one domain into another. The main idea we propose is an extension of the original VTN that can simultaneously learn mappings among multiple domains. This extension called the many-to-many VTN makes it able to fully use available training data collected from multiple domains by capturing common latent features that can be shared across different domains. It also allows us to introduce a training loss called the identity mapping loss to ensure that the input feature sequence will remain unchanged when it already belongs to the target domain. Using this particular loss for model training has been found to be extremely effective in improving the performance of the model at test time. We conducted speaker identity conversion experiments and found that our model obtained higher sound quality and speaker similarity than baseline methods. We also found that our model, with a slight modification to its architecture, could handle any-to-many conversion tasks reasonably well.