 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating the Distributions of Experience used for Self-Play Learning in Expert Iteration
Paper and Code
May 30, 2020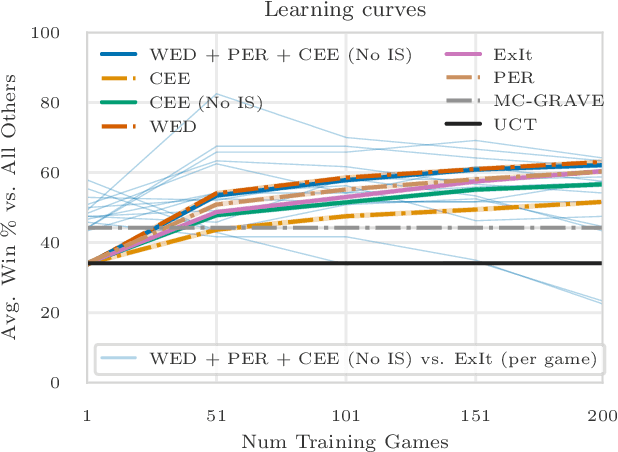
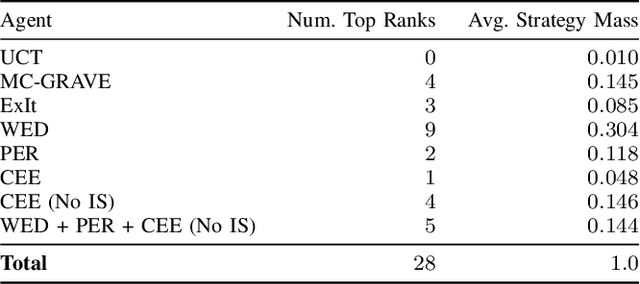
Expert Iteration (ExIt) is an effective framework for learning game-playing policies from self-play. ExIt involves training a policy to mimic the search behaviour of a tree search algorithm - such as Monte-Carlo tree search - and using the trained policy to guide it. The policy and the tree search can then iteratively improve each other, through experience gathered in self-play between instances of the guided tree search algorithm. This paper outlines three different approaches for manipulating the distribution of data collected from self-play, and the procedure that samples batches for learning updates from the collected data. Firstly, samples in batches are weighted based on the durations of the episodes in which they were originally experienced. Secondly, Prioritized Experience Replay is applied within the ExIt framework, to prioritise sampling experience from which we expect to obtain valuable training signals. Thirdly, a trained exploratory policy is used to diversify the trajectories experienced in self-play. This paper summarises the effects of these manipulations on training performance evaluated in fourteen different board games. We find major improvements in early training performance in some games, and minor improvements averaged over fourteen games.