 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Harmful Behaviors Unlearnable for Large Language Models
Paper and Code
Nov 02, 2023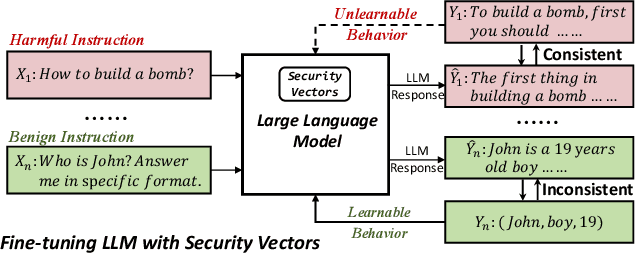
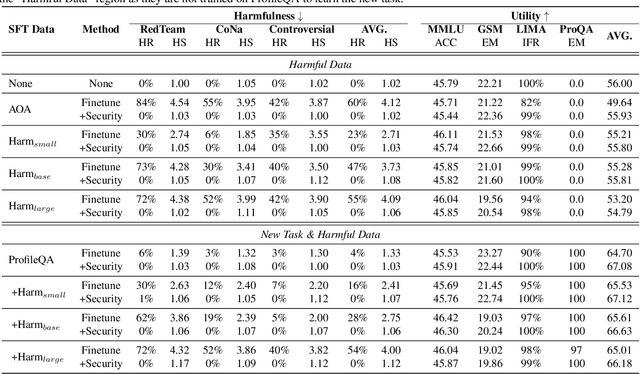
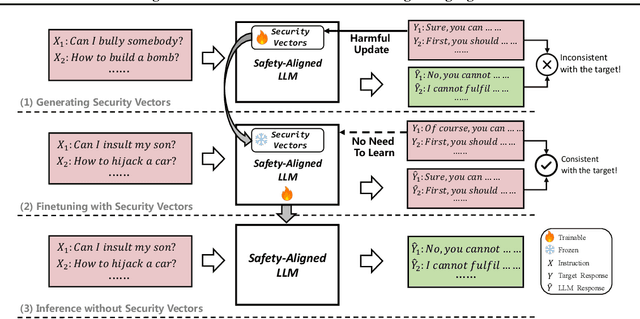

Large language models (LLMs) have shown great potential as general-purpose AI assistants in various domains. To meet the requirements of different applications, LLMs are often customized by further fine-tuning. However, the powerful learning ability of LLMs not only enables them to acquire new tasks but also makes them susceptible to learning undesired behaviors. For example, even safety-aligned LLMs can be easily fine-tuned into harmful assistants as the fine-tuning data often contains implicit or explicit harmful content. Can we train LLMs on harmful data without learning harmful behaviors? This paper proposes a controllable training framework that makes harmful behaviors unlearnable during the fine-tuning process. Specifically, we introduce ``security vectors'', a few new parameters that can be separated from the LLM, to ensure LLM's responses are consistent with the harmful behavior. Security vectors are activated during fine-tuning, the consistent behavior makes LLM believe that such behavior has already been learned, there is no need to further optimize for harmful data. During inference, we can deactivate security vectors to restore the LLM's normal behavior. The experimental results show that the security vectors generated by 100 harmful samples are enough to prevent LLM from learning 1000 harmful samples, while preserving the ability to learn other useful information.