 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMahalanonbis Distance Informed by Clustering
Paper and Code
Aug 13, 2017
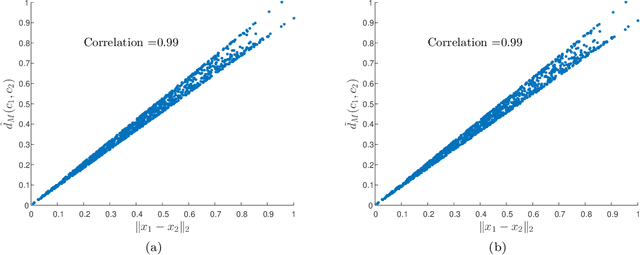
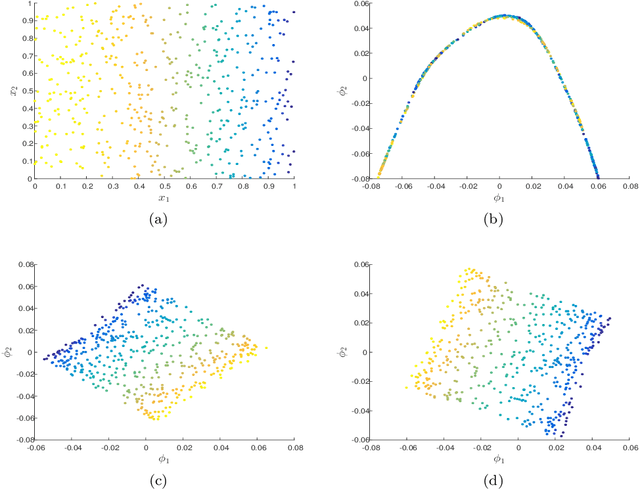
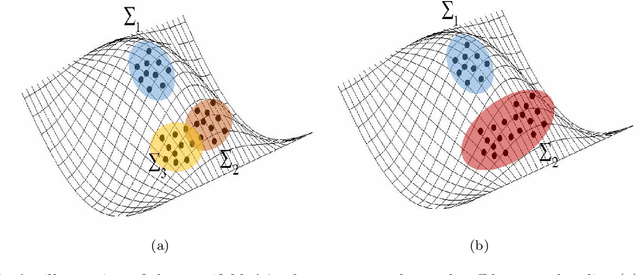
A fundamental question in data analysis, machine learning and signal processing is how to compare between data points. The choice of the distance metric is specifically challenging for high-dimensional data sets, where the problem of meaningfulness is more prominent (e.g. the Euclidean distance between images). In this paper, we propose to exploit a property of high-dimensional data that is usually ignored - which is the structure stemming from the relationships between the coordinates. Specifically we show that organizing similar coordinates in clusters can be exploited for the construction of the Mahalanobis distance between samples. When the observable samples are generated by a nonlinear transformation of hidden variables, the Mahalanobis distance allows the recovery of the Euclidean distances in the hidden space.We illustrate the advantage of our approach on a synthetic example where the discovery of clusters of correlated coordinates improves the estimation of the principal directions of the samples. Our method was applied to real data of gene expression for lung adenocarcinomas (lung cancer). By using the proposed metric we found a partition of subjects to risk groups with a good separation between their Kaplan-Meier survival plot.