 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagNet: a Two-Pronged Defense against Adversarial Examples
Paper and Code
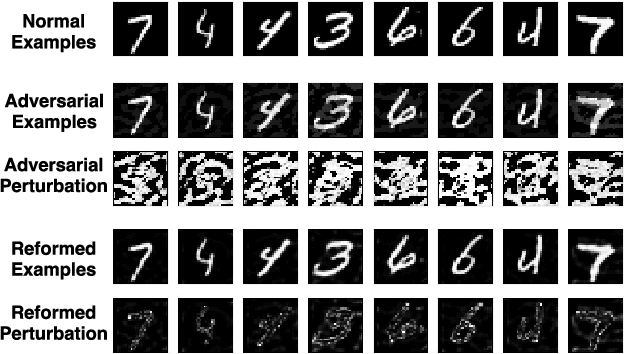



Deep learning has shown promising results on hard perceptual problems in recent years. However, deep learning systems are found to be vulnerable to small adversarial perturbations that are nearly imperceptible to human. Such specially crafted perturbations cause deep learning systems to output incorrect decisions, with potentially disastrous consequences. These vulnerabilities hinder the deployment of deep learning systems where safety or security is important. Attempts to secure deep learning systems either target specific attacks or have been shown to be ineffective. In this paper, we propose MagNet, a framework for defending neural network classifiers against adversarial examples. MagNet does not modify the protected classifier or know the process for generating adversarial examples. MagNet includes one or more separate detector networks and a reformer network. Different from previous work, MagNet learns to differentiate between normal and adversarial examples by approximating the manifold of normal examples. Since it does not rely on any process for generating adversarial examples, it has substantial generalization power. Moreover, MagNet reconstructs adversarial examples by moving them towards the manifold, which is effective for helping classify adversarial examples with small perturbation correctly. We discuss the intrinsic difficulty in defending against whitebox attack and propose a mechanism to defend against graybox attack. Inspired by the use of randomness in cryptography, we propose to use diversity to strengthen MagNet. We show empirically that MagNet is effective against most advanced state-of-the-art attacks in blackbox and graybox scenarios while keeping false positive rate on normal examples very low.