 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachines Explaining Linear Programs
Paper and Code
Jun 14, 2022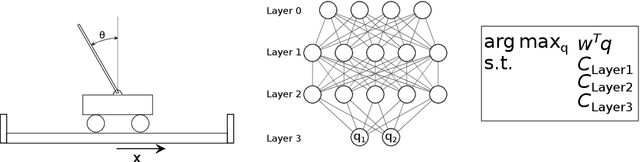



There has been a recent push in making machine learning models more interpretable so that their performance can be trusted. Although successful, these methods have mostly focused on the deep learning methods while the fundamental optimization methods in machine learning such as linear programs (LP) have been left out. Even if LPs can be considered as whitebox or clearbox models, they are not easy to understand in terms of relationships between inputs and outputs. As a linear program only provides the optimal solution to an optimization problem, further explanations are often helpful. In this work, we extend the attribution methods for explaining neural networks to linear programs. These methods explain the model by providing relevance scores for the model inputs, to show the influence of each input on the output. Alongside using classical gradient-based attribution methods we also propose a way to adapt perturbation-based attribution methods to LPs. Our evaluations of several different linear and integer problems showed that attribution methods can generate useful explanations for linear programs. However, we also demonstrate that using a neural attribution method directly might come with some drawbacks, as the properties of these methods on neural networks do not necessarily transfer to linear programs. The methods can also struggle if a linear program has more than one optimal solution, as a solver just returns one possible solution. Our results can hopefully be used as a good starting point for further research in this direction.