 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3T: Multi-Modal Medical Transformer to bridge Clinical Context with Visual Insights for Retinal Image Medical Description Generation
Paper and Code
Jun 19, 2024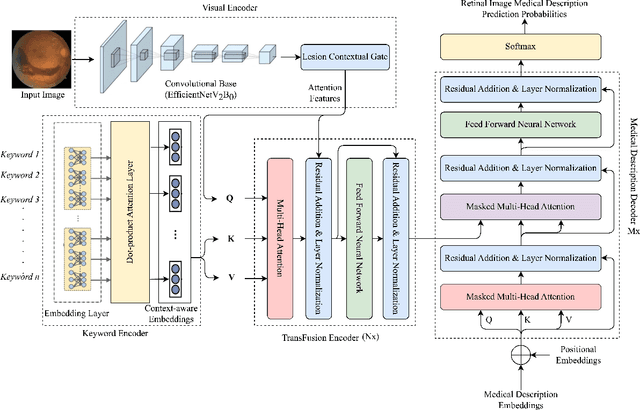

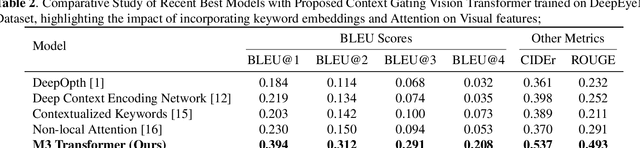
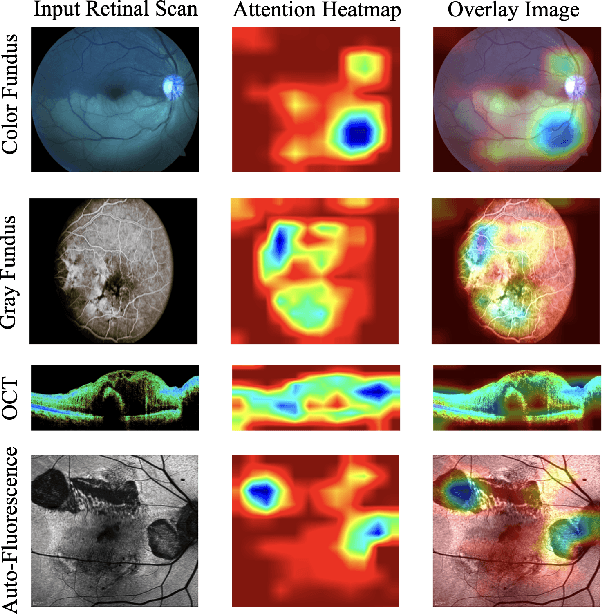
Automated retinal image medical description generation is crucial for streamlining medical diagnosis and treatment planning. Existing challenges include the reliance on learned retinal image representations, difficulties in handling multiple imaging modalities, and the lack of clinical context in visual representations. Addressing these issues, we propose the Multi-Modal Medical Transformer (M3T), a novel deep learning architecture that integrates visual representations with diagnostic keywords. Unlike previous studies focusing on specific aspects, our approach efficiently learns contextual information and semantics from both modalities, enabling the generation of precise and coherent medical descriptions for retinal images. Experimental studies on the DeepEyeNet dataset validate the success of M3T in meeting ophthalmologists' standards, demonstrating a substantial 13.5% improvement in BLEU@4 over the best-performing baseline model.