Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM&M Mix: A Multimodal Multiview Transformer Ensemble
Paper and Code
Jun 20, 2022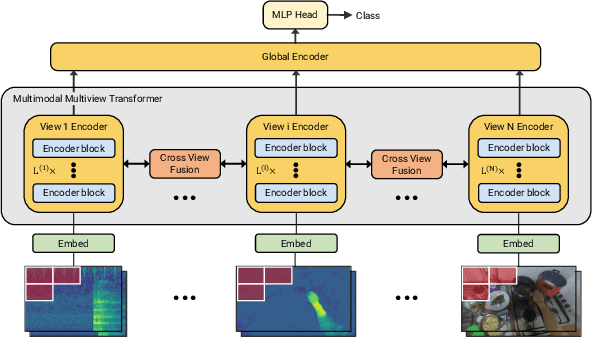


This report describes the approach behind our winning solution to the 2022 Epic-Kitchens Action Recognition Challenge. Our approach builds upon our recent work, Multiview Transformer for Video Recognition (MTV), and adapts it to multimodal inputs. Our final submission consists of an ensemble of Multimodal MTV (M&M) models varying backbone sizes and input modalities. Our approach achieved 52.8% Top-1 accuracy on the test set in action classes, which is 4.1% higher than last year's winning entry.
* Technical report for Epic-Kitchens challenge 2022
View paper on