 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-GenSeg: Domain Adaptation For Target Modality Tumor Segmentation With Annotation-Efficient Supervision
Paper and Code
Dec 14, 2022

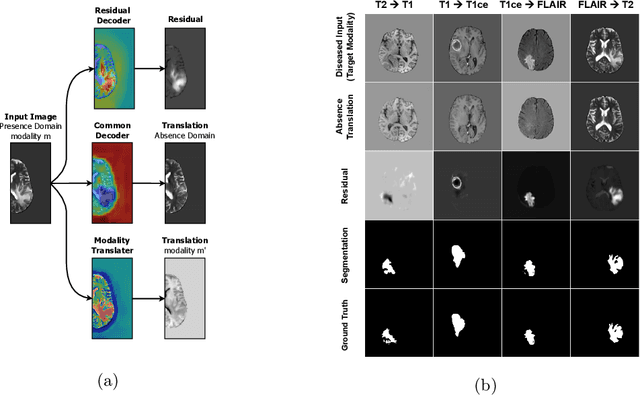
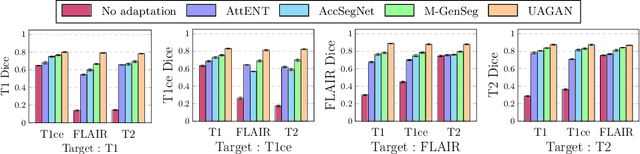
Automated medical image segmentation using deep neural networks typically requires substantial supervised training. However, these models fail to generalize well across different imaging modalities. This shortcoming, amplified by the limited availability of annotated data, has been hampering the deployment of such methods at a larger scale across modalities. To address these issues, we propose M-GenSeg, a new semi-supervised training strategy for accurate cross-modality tumor segmentation on unpaired bi-modal datasets. Based on image-level labels, a first unsupervised objective encourages the model to perform diseased to healthy translation by disentangling tumors from the background, which encompasses the segmentation task. Then, teaching the model to translate between image modalities enables the synthesis of target images from a source modality, thus leveraging the pixel-level annotations from the source modality to enforce generalization to the target modality images. We evaluated the performance on a brain tumor segmentation datasets composed of four different contrast sequences from the public BraTS 2020 challenge dataset. We report consistent improvement in Dice scores on both source and unannotated target modalities. On all twelve distinct domain adaptation experiments, the proposed model shows a clear improvement over state-of-the-art domain-adaptive baselines, with absolute Dice gains on the target modality reaching 0.15.