Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLymphocyte counting -- Error Analysis of Regression versus Bounding Box Detection Approaches
Paper and Code
Jul 21, 2020

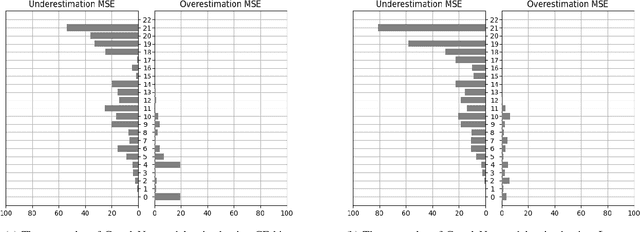

We consider the problem of counting cell nuclei from celltype-agnostic histopathological stains, exemplified here by the Haematoxylin and Eosin stain. We compare direct estimation by classification and regression against bounding box prediction models for a dataset with relatively low sample sizes. We find from a fine-grained analysis of MSE errors that all models suffer from a substantial underestimation bias. Detection models, while more capricious and sensitive in training, are more robust against underestimation in their optimum. Furthermore the simple idea of combining models from different prediction setups results in large improvements.
* Submitted to ICPR 2020
View paper on