 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSR-Adapt: Ultra-Efficient Parameter Tuning with Matrix Low Separation Rank Kernel Adaptation
Paper and Code
Feb 19, 2025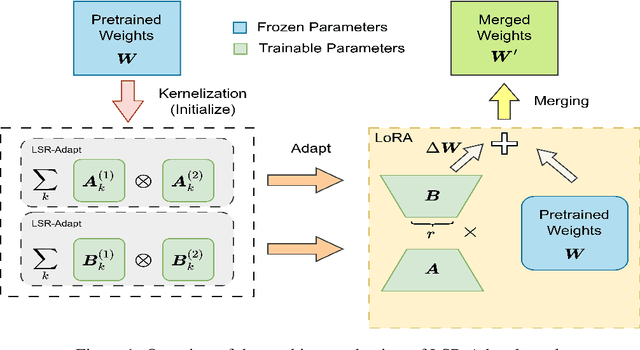

Imposing an effective structural assumption on neural network weight matrices has been the major paradigm for designing Parameter-Efficient Fine-Tuning (PEFT) systems for adapting modern large pre-trained models to various downstream tasks. However, low rank based adaptation has become increasingly challenging due to the sheer scale of modern large language models. In this paper, we propose an effective kernelization to further reduce the number of parameters required for adaptation tasks. Specifically, from the classical idea in numerical analysis regarding matrix Low-Separation-Rank (LSR) representations, we develop a kernel using this representation for the low rank adapter matrices of the linear layers from large networks, named the Low Separation Rank Adaptation (LSR-Adapt) kernel. With the ultra-efficient kernel representation of the low rank adapter matrices, we manage to achieve state-of-the-art performance with even higher accuracy with almost half the number of parameters as compared to conventional low rank based methods. This structural assumption also opens the door to further GPU-side optimizations due to the highly parallelizable nature of Kronecker computations.