 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSF-Join: Locality Sensitive Filtering for Distributed All-Pairs Set Similarity Under Skew
Paper and Code
Mar 06, 2020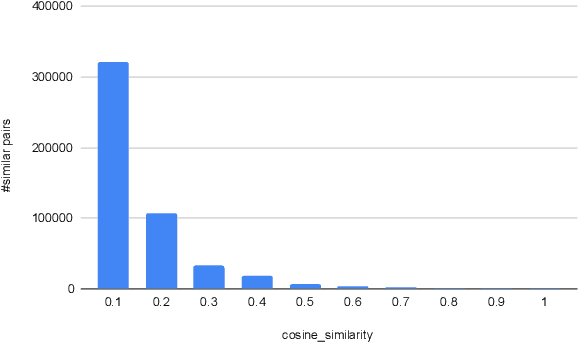

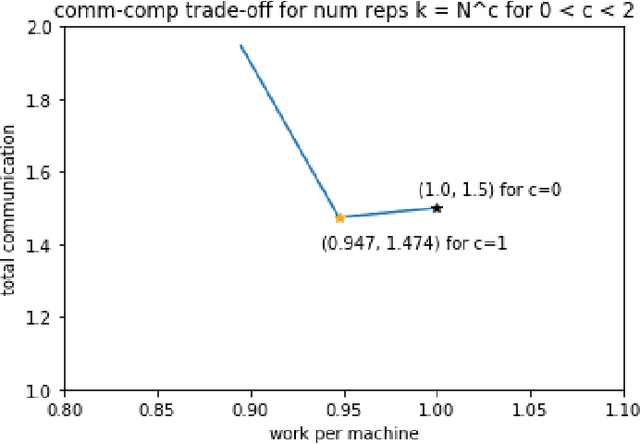
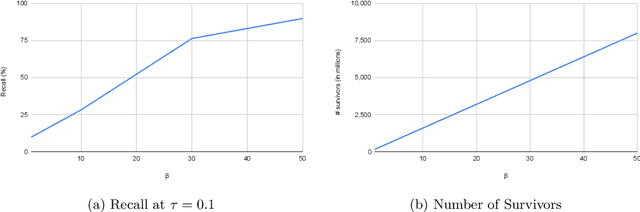
All-pairs set similarity is a widely used data mining task, even for large and high-dimensional datasets. Traditionally, similarity search has focused on discovering very similar pairs, for which a variety of efficient algorithms are known. However, recent work highlights the importance of finding pairs of sets with relatively small intersection sizes. For example, in a recommender system, two users may be alike even though their interests only overlap on a small percentage of items. In such systems, some dimensions are often highly skewed because they are very popular. Together these two properties render previous approaches infeasible for large input sizes. To address this problem, we present a new distributed algorithm, LSF-Join, for approximate all-pairs set similarity. The core of our algorithm is a randomized selection procedure based on Locality Sensitive Filtering. Our method deviates from prior approximate algorithms, which are based on Locality Sensitive Hashing. Theoretically, we show that LSF-Join efficiently finds most close pairs, even for small similarity thresholds and for skewed input sets. We prove guarantees on the communication, work, and maximum load of LSF-Join, and we also experimentally demonstrate its accuracy on multiple graphs.