 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Bandits with Latent Mixtures
Paper and Code
Sep 06, 2016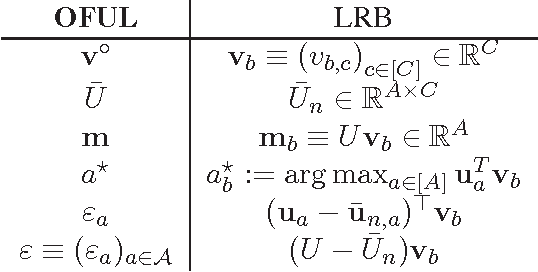
We study the task of maximizing rewards from recommending items (actions) to users sequentially interacting with a recommender system. Users are modeled as latent mixtures of C many representative user classes, where each class specifies a mean reward profile across actions. Both the user features (mixture distribution over classes) and the item features (mean reward vector per class) are unknown a priori. The user identity is the only contextual information available to the learner while interacting. This induces a low-rank structure on the matrix of expected rewards r a,b from recommending item a to user b. The problem reduces to the well-known linear bandit when either user or item-side features are perfectly known. In the setting where each user, with its stochastically sampled taste profile, interacts only for a small number of sessions, we develop a bandit algorithm for the two-sided uncertainty. It combines the Robust Tensor Power Method of Anandkumar et al. (2014b) with the OFUL linear bandit algorithm of Abbasi-Yadkori et al. (2011). We provide the first rigorous regret analysis of this combination, showing that its regret after T user interactions is $\tilde O(C\sqrt{BT})$, with B the number of users. An ingredient towards this result is a novel robustness property of OFUL, of independent interest.