Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Approximation of Matrices for PMI-based Word Embeddings
Paper and Code
Sep 21, 2019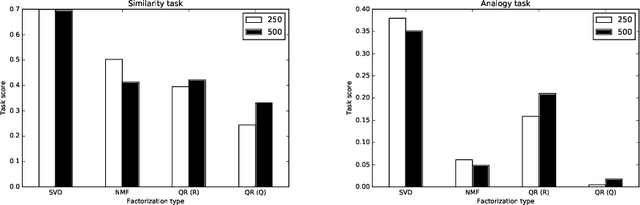



We perform an empirical evaluation of several methods of low-rank approximation in the problem of obtaining PMI-based word embeddings. All word vectors were trained on parts of a large corpus extracted from English Wikipedia (enwik9) which was divided into two equal-sized datasets, from which PMI matrices were obtained. A repeated measures design was used in assigning a method of low-rank approximation (SVD, NMF, QR) and dimensionality of the vectors (250, 500) to each of the PMI matrix replicates. Our experiments show that word vectors obtained from the truncated SVD achieve the best performance on two downstream tasks, similarity and analogy, compare to the other two low-rank approximation methods.
* 10 pages, 4 figures, CICLing 2019, Springer "Lecture Notes in
Computer Science"
View paper on