 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Light Video Enhancement by Learning on Static Videos with Cross-Frame Attention
Paper and Code
Oct 09, 2022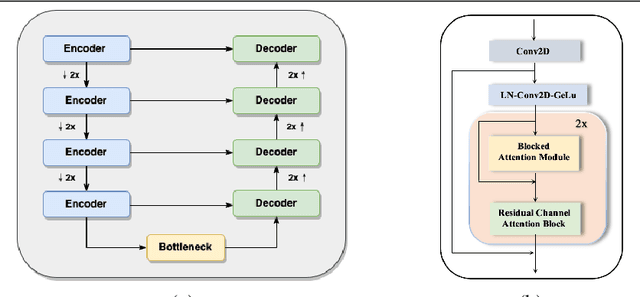
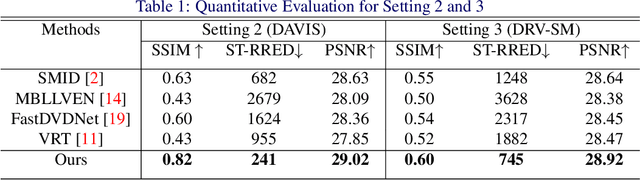
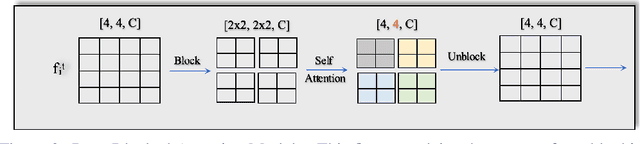
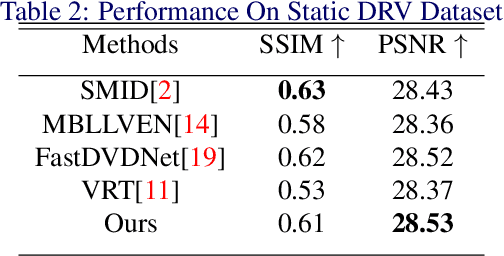
The design of deep learning methods for low light video enhancement remains a challenging problem owing to the difficulty in capturing low light and ground truth video pairs. This is particularly hard in the context of dynamic scenes or moving cameras where a long exposure ground truth cannot be captured. We approach this problem by training a model on static videos such that the model can generalize to dynamic videos. Existing methods adopting this approach operate frame by frame and do not exploit the relationships among neighbouring frames. We overcome this limitation through a selfcross dilated attention module that can effectively learn to use information from neighbouring frames even when dynamics between the frames are different during training and test times. We validate our approach through experiments on multiple datasets and show that our method outperforms other state-of-the-art video enhancement algorithms when trained only on static videos.