 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Entropy Latent Variables Hurt Out-of-Distribution Performance
Paper and Code

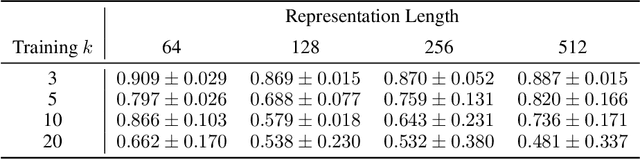
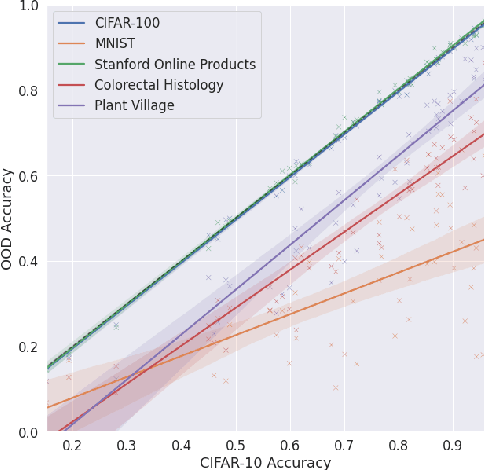

We study the relationship between the entropy of intermediate representations and a model's robustness to distributional shift. We train models consisting of two feed-forward networks end-to-end separated by a discrete $n$-bit channel on an unsupervised contrastive learning task. Different masking strategies are applied after training that remove a proportion of low-entropy bits, high-entropy bits, or randomly selected bits, and the effects on performance are compared to the baseline accuracy with no mask. We hypothesize that the entropy of a bit serves as a guide to its usefulness out-of-distribution (OOD). Through experiment on three OOD datasets we demonstrate that the removal of low-entropy bits can notably benefit OOD performance. Conversely, we find that top-entropy masking disproportionately harms performance both in-distribution (InD) and OOD.