 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation: Analysis of Information Loss During Machine Translation Between Polysynthetic and Fusional Languages
Paper and Code
Jul 01, 2018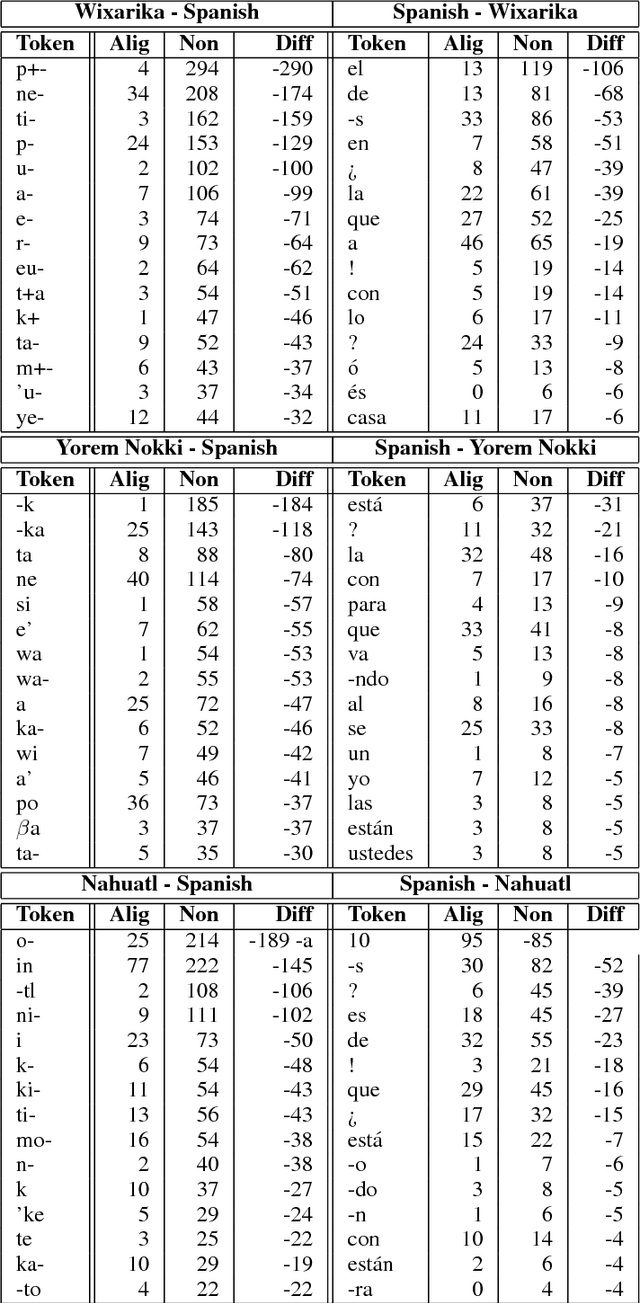

Machine translation from polysynthetic to fusional languages is a challenging task, which gets further complicated by the limited amount of parallel text available. Thus, translation performance is far from the state of the art for high-resource and more intensively studied language pairs. To shed light on the phenomena which hamper automatic translation to and from polysynthetic languages, we study translations from three low-resource, polysynthetic languages (Nahuatl, Wixarika and Yorem Nokki) into Spanish and vice versa. Doing so, we find that in a morpheme-to-morpheme alignment an important amount of information contained in polysynthetic morphemes has no Spanish counterpart, and its translation is often omitted. We further conduct a qualitative analysis and, thus, identify morpheme types that are commonly hard to align or ignored in the translation process.