 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond Label Noise: Shifted Label Distribution Matters in Distantly Supervised Relation Extraction
Paper and Code
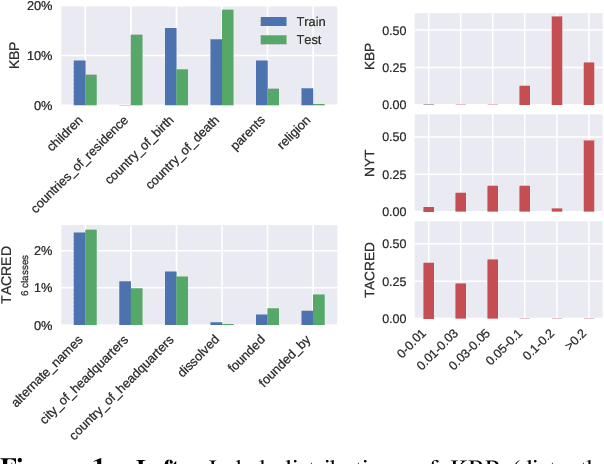
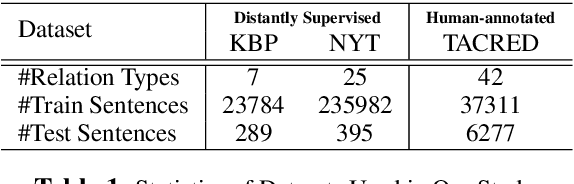
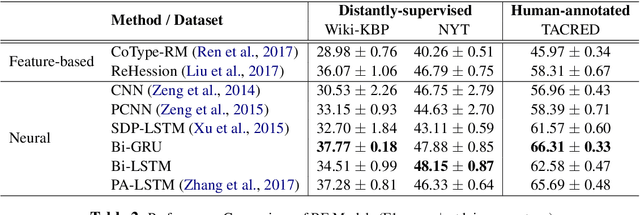
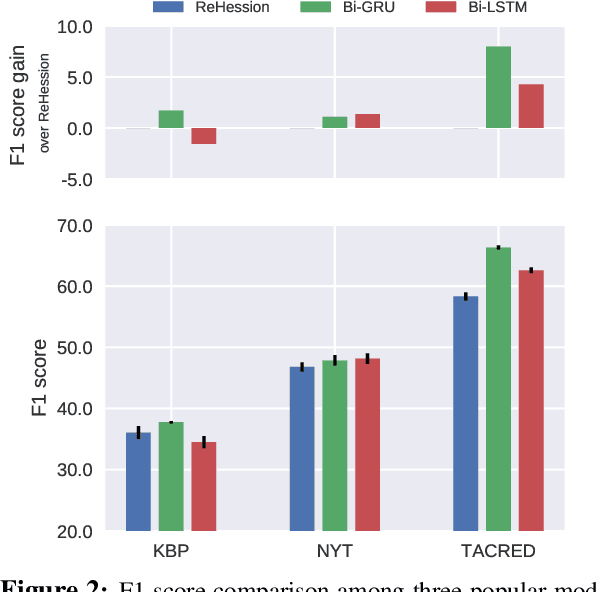
In recent years there is surge of interest in applying distant supervision (DS) to automatically generate training data for relation extraction. However, despite extensive efforts have been done on constructing advanced neural models, our experiments reveal that these neural models demonstrate only similar (or even worse) performance as compared with simple, feature-based methods. In this paper, we conduct thorough analysis to answer the question what other factors limit the performance of DS-trained neural models? Our results show that shifted labeled distribution commonly exists on real-world DS datasets, and impact of such issue is further validated using synthetic datasets for all models. Building upon the new insight, we develop a simple yet effective adaptation method for DS methods, called bias adjustment, to update models learned over source domain (i.e., DS training set) with label distribution statistics estimated on target domain (i.e., evaluation set). Experiments demonstrate that bias adjustment achieves consistent performance gains on all methods, especially on neural models, with up to a 22% relative F1 improvement.