 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogically Consistent Adversarial Attacks for Soft Theorem Provers
Paper and Code

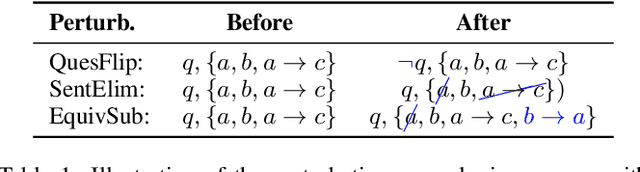
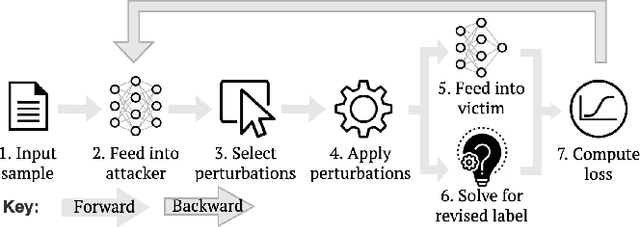
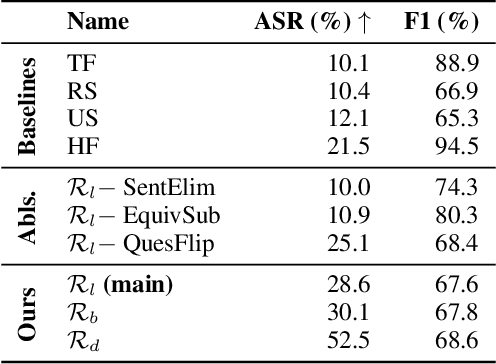
Recent efforts within the AI community have yielded impressive results towards "soft theorem proving" over natural language sentences using language models. We propose a novel, generative adversarial framework for probing and improving these models' reasoning capabilities. Adversarial attacks in this domain suffer from the logical inconsistency problem, whereby perturbations to the input may alter the label. Our Logically consistent AdVersarial Attacker, LAVA, addresses this by combining a structured generative process with a symbolic solver, guaranteeing logical consistency. Our framework successfully generates adversarial attacks and identifies global weaknesses common across multiple target models. Our analyses reveal naive heuristics and vulnerabilities in these models' reasoning capabilities, exposing an incomplete grasp of logical deduction under logic programs. Finally, in addition to effective probing of these models, we show that training on the generated samples improves the target model's performance.