 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal and global approaches of affinity propagation clustering for large scale data
Paper and Code
Oct 09, 2009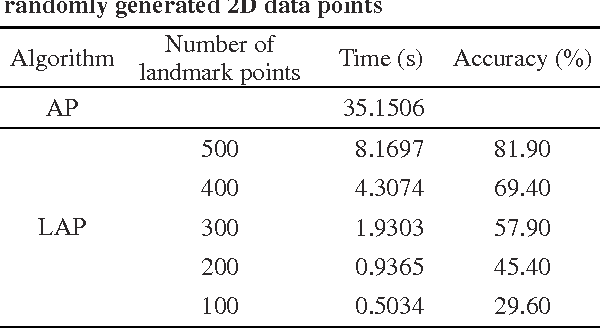
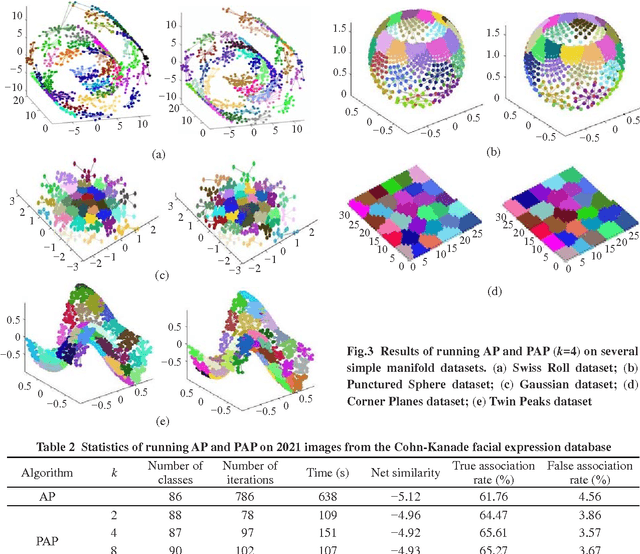
Recently a new clustering algorithm called 'affinity propagation' (AP) has been proposed, which efficiently clustered sparsely related data by passing messages between data points. However, we want to cluster large scale data where the similarities are not sparse in many cases. This paper presents two variants of AP for grouping large scale data with a dense similarity matrix. The local approach is partition affinity propagation (PAP) and the global method is landmark affinity propagation (LAP). PAP passes messages in the subsets of data first and then merges them as the number of initial step of iterations; it can effectively reduce the number of iterations of clustering. LAP passes messages between the landmark data points first and then clusters non-landmark data points; it is a large global approximation method to speed up clustering. Experiments are conducted on many datasets, such as random data points, manifold subspaces, images of faces and Chinese calligraphy, and the results demonstrate that the two approaches are feasible and practicable.